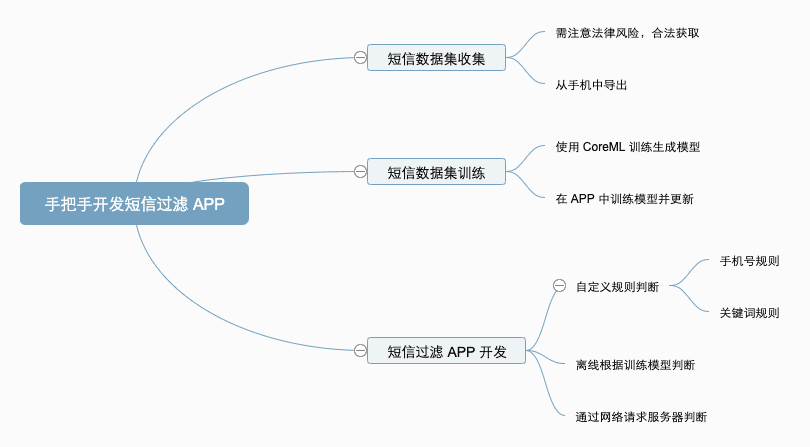
短信過濾 APP 開發#
本文發布在搜狐技術產品 - 短信過濾 APP 開發
一直想開發一個自己的短信過濾 APP,但是一直沒有具體實施,現在終於靜下心來,邊開發邊記錄下整體的開發過程。
垃圾短信樣本#
遇到的第一個問題是,既然要過濾垃圾短信,那首先要識別哪些是垃圾短信?如何識別呢?
參考之前訓練識別鋼管計數的經驗,決定通過 CoreML 訓練 Text 模型來識別,那問題來了,要訓練模型的短信數據集怎麼來?
一開始打算網上找到垃圾短信樣本,但找了好久沒找到,於是就想到用自己和家人手機裡的短信,畢竟手機裡短信一般不刪除,也有小幾千條,而且垃圾短信、推銷、廣告之類的應有盡有。
所以問題就變成了,如何導出 iPhone 短信?
這裡筆者也查了好久,找到的第三方軟件基本都是需要收費,最終發現了一個免費導出的方案。
首先不加密備份手機到電腦,如下圖,選中Back up all the data on your iPhone to this Mac,點擊Back Up Now,等待備份完成,備份完成後,再點擊Manage Backups

Manage Backups點擊後,界面如下,可以看到已備份的記錄,右鍵選擇Show In Finder,在文件夾中打開

然後可以看到備份所在目錄已打開,這時需要找到文件名為3d0d7e5fb2ce288813306e4d4636395e047a3d28的文件,這個文件就是短信備份的數據庫文件。然後問題來了,怎麼找呢?看到備份目錄一個個文件夾是不是懵,這怎麼找,很簡單,搜索,點擊右上角的搜索,直接把這個文件名輸入即可,注意搜索的範圍是當前文件夾,

搜索結果如下:

然後把這個文件單獨拷貝到另一個地方,比如桌面,再用數據庫軟件打開,比如SQLPro for SQLLite,打開如下:

然後觀察這個文件後發現,手機號和短信記錄分布在不同表中,需要寫一個 SQL 查出需要的內容,SQL 內容如下,參考SQL to extract messages from backup,選中上圖中Query,輸入命令如下:
SELECT datetime(message.date, 'unixepoch', '+31 years', '-6 hours') as Timestamp, handle.id, message.text,
case when message.is_from_me then 'From me' else 'To me' end as Sender
FROM message, handle WHERE message.handle_id = handle.ROWID AND message.text NOT NULL;
然後點擊右上角的執行,可以看到,把短信都篩選出來了

然後選中所有 row,右鍵選擇Export result set as 導出CSV,即可導出 excel 格式的文件。

這樣就獲取到了所需的短信樣本。
垃圾短信訓練識別#
有了樣本之後,再來看如何訓練識別,打算使用蘋果的 CoreML 識別,那麼如何使用?樣本格式的要求是什麼樣?訓練需要多久?
先來看,創建一個文字訓練的CoreML工程,選中 Xcode,點擊Open Developer Tool,選中CoreML打開,如下圖:

然後選擇文件夾,並點擊新建New Document, 如下:

然後選中Text Classification,如下圖:

接著輸入項目的名字和描述,

點擊右下角創建,進入主界面,如下

點擊Traing Data的詳細說明,可以看到CoreML要求的文字識別的格式,支持JSON和CSV文件,格式如下:

JSON 格式如下:
// JSON file
[
{
"text": "The movie was fantastic!",
"label": "positive"
}, {
"text": "Very boring. Fell asleep.",
"label": "negative"
}, {
"text": "It was just OK.",
"label": "neutral"
} ...
]
而 CSV 格式則是,一列text,一列label,
| text | label |
|---|---|
| 這是一條普通短信 | label1 |
| 這是一條垃圾短信 | label2 |
由於再前一步中,已經將短信導出為 CSV 格式,所以這裡就需要把格式改為上圖中格式即可,只剩下一個問題需要解決,即:label 有哪些取值?
要看 label 有哪些取值,需要先看系統短信的過濾邏輯是什麼樣?支持的過濾分類有哪些?否則自己想實現的分類,分組好了,最後發現系統不支持就尷尬了。
短信過濾分類#
系統短信的過濾邏輯#
參考SMS and MMS Message Filtering,可以看到,開發者是沒有權限創建新分組的,只能是針對收到未知聯繫人的SMS或者MMS,攔截返回指定的分類。
這裡需要注意的是,根據文檔的說法,短信過濾不支持 iMessage 和通訊錄中聯繫人的短信的過濾,僅支持未知聯繫人的SMS和MMS。
短信過濾,又分為本地判斷過濾和服務端判斷過濾,示意圖如下:
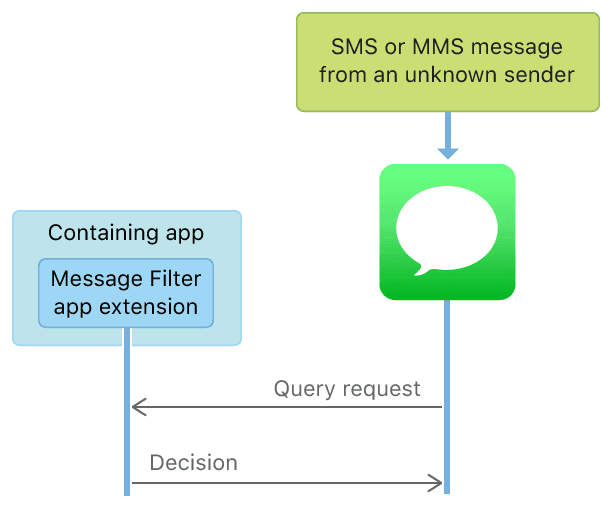
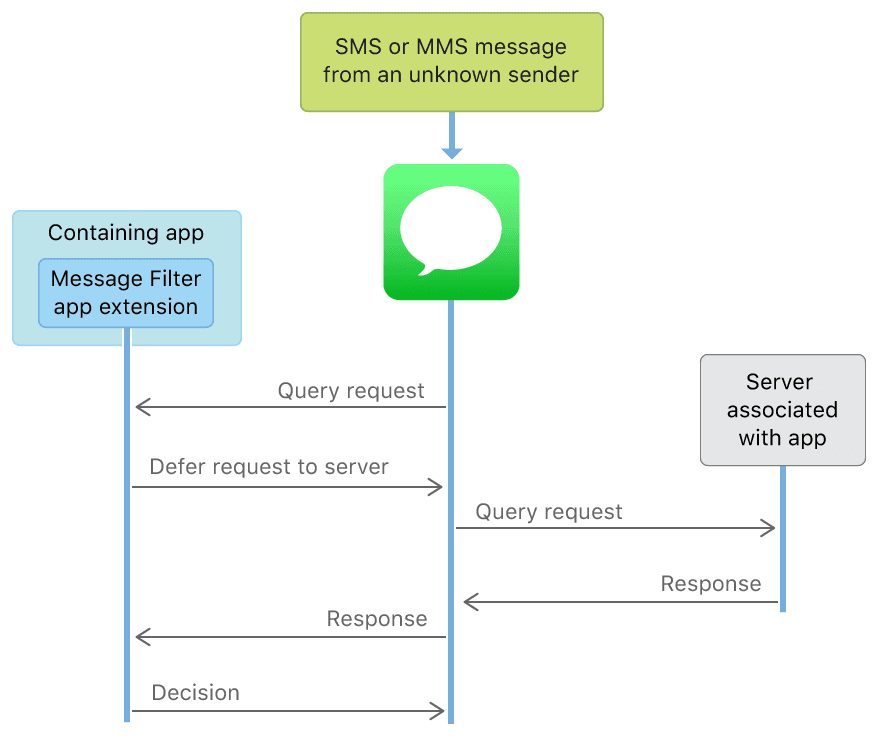
按照文檔的說法,即使是服務端過濾,APP 也是不能直接訪問網絡的,系統會和設置的伺服器交互;而且 App Extension 不能通過共享 Group 寫數據,故而短信僅能在 App Extension 中獲取到,不能存儲,不能上傳,從而保證隱私和安全。關於服務端過濾更多的實現,可以參考Creating a Message Filter App Extension。
再來看支持的過濾類型,ILMessageFilterAction
大分類支持五種:
- none
沒有足夠信息,不能判斷,會展示信息,或進一步請求服務端判斷過濾 - allow
正常展示信息 - junk
阻止正常展示信息,顯示在垃圾短信分類下 - promotion
阻止正常展示信息,顯示在推送信息分類下 - transation
阻止正常展示信息,顯示在交易信息分類下
而其中又可以細分子分類,ILMessageFilterSubAction,具體含義可以參考ILMessageFilterSubAction
- none
- promotion 支持的子分類有
- others
- offers
- coupons
- transation 支持的子分類有
- others
- finance
- orders
- reminders
- health
- weather
- carrier
- rewards
- publicServices
這裡僅針對大分類做處理,具體的子分類不做詳細過濾,所以需要訓練的 label 有哪些取值就很明確了,過濾垃圾短信、推廣信息、交易信息,至於 none 和 allow 不做區分,統一處理為 allow,所以總共需要訓練的 label 取值有以下這些:
- allow
- junk
- promotion
- transation
然後就是針對導出短信的CSV文件,針對每條短信,添加對應的 label,這裡只能手工,樣本的大小和 label 定義決定後續識別的準確度,同時為了後續子分類的實現,建議實事求是,不要把比如 promotion 裡的分到 junk 裡。。。
每條短信樣本都標記好了之後,就可以導入Create ML來訓練,生成需要的模型,步驟如下:
首先導入數據集

然後點擊左上角的Train

等訓練好了之後,可以點擊 Preview,模擬短信文本,看輸出的預測,如下圖:

最後,導出模型,供 APP 使用

APP 開發#
新建項目,然後使用new bing 生成圖片來設計 APPIcon,再用 ChatGPT-4,來生成 APP 名字。然後添加Message Filter Extension Target,如下圖:

在 MessageFilterExtension.swift 中,能看到蘋果已經幫忙實現了基本的框架,只需要在框架對應 // TODO: 的地方,加入對應的過濾邏輯即可。
然後導入訓練結果集到項目中,注意 Target 要勾選主工程和Message Filter Extension 的 Target,因為需要在這個 Target 中使用模型來實現過濾。
具體使用如下:
import Foundation
import IdentityLookup
import CoreML
import IdentityLookup
enum SMSFilterActionType: String {
case transation
case promotion
case allow
case junk
func formatFilterAction() -> ILMessageFilterAction {
switch self {
case .transation:
return ILMessageFilterAction.transaction
case .promotion:
return ILMessageFilterAction.promotion
case .allow:
return ILMessageFilterAction.allow
case .junk:
return ILMessageFilterAction.junk
}
}
}
struct SMSFilterUtil {
static func filter(with messageBody: String) -> ILMessageFilterAction {
var filterAction: ILMessageFilterAction = .none
let configuration = MLModelConfiguration()
do {
let model = try SmsClassifier(configuration: configuration)
let resultLabel = try model.prediction(text: messageBody).label
if let resultFilterAction = SMSFilterActionType(rawValue: resultLabel)?.formatFilterAction() {
filterAction = resultFilterAction
}
} catch {
print(error)
}
return filterAction
}
}
然後在MessageFilterExtension.Swift中offlineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction)方法調用,如下:
@available(iOSApplicationExtension 16.0, *)
private func offlineAction(for queryRequest: ILMessageFilterQueryRequest) -> (ILMessageFilterAction, ILMessageFilterSubAction) {
guard let messageBody = queryRequest.messageBody else {
return (.none, .none)
}
let action = MWSMSFilterUtil.filter(with: messageBody)
return (action, .none)
}
這裡需要注意下 APP 最低版本設置,ILMessageFilterSubAction只有 iOS 16 以上的手機才支持,而ILMessageFilterSubAction則是 iOS 14 以上。
如果想實現更精細的SubAction的過濾,則上面短信數據集的 label 需要改為更精細的 label,然後訓練出模型,再用來判斷。
另外,ILMessageFilterQueryRequest中可以獲取到sender和messageBody,所以如果想實現自定義規則,比如針對某個手機號設置對應的規則,則需要從 APP 中設置對應的規則,然後通過 Group 共享到 Extension,然後在上面的方法裡通過規則匹配。
總結#
相信通過上面的步驟,大家都能開發出自己的短信過濾 APP。
上面的步驟是通過固定的訓練模型來匹配的邏輯,步驟是:
- 獲取短信數據集
- 通過 CoreML 使用數據集訓練並生成模型
- 在項目中使用模型,進行判斷
這種方式生成的模型其數據固定,每次更新模型需要重新訓練並導入,然後更新 APP。是否有更好的方式呢?
比如是否可以在 APP 中邊訓練邊更新?又或者是否可以通過本地規則加本地模型加網絡模型這種方式?
假設方案一:
首先,在 APP 中邊訓練邊更新,大概思路如下:
更新模型,需要知道一條數據的內容和數據的分類,所以如果要在 APP 中訓練模型,就需要通過另外的辦法獲取到分類,要不然用模型得到分類再回過頭來訓練模型,意義不大。所以通過自定義規則獲取到數據分類,然後用數據和數據分類來更新模型,這種方式應該是可行的。
假設方案二:
然後來考慮更完善的一種方式,即通過本地規則加本地模型加網絡模型的方式:
邏輯是首先通過本地規則匹配,如果本地規則匹配不到,則繼續使用本地模型匹配,如果本地模型也匹配不到,則通過請求服務端,服務端另有一套不斷訓練更新的模型,來獲取對應的分類,最後每次更新時把服務端當前對應最新的模型更新到項目中。
假設方案三:
方案二需要通過網絡模型,假設的前提是服務端有一套不斷訓練更新的模型,那如果這個假設不存在?只有本地規則和本地模型,外加偶爾獲取到的更新數據集,是否有辦法在線更新本地模型?
目前本地模型是直接添加到 APP 主 Bundle 中,可以考慮在首次啟動時拷貝到 APP 和 Extension 的共享 Group 中,每次打開 APP 時,判斷模型是否有更新,有更新則下載替換這個目錄下的模型文件。在 Extension 中,通過 URL 獲取這個目錄下的模型文件來進行過濾。
幾種方案流程圖如下:
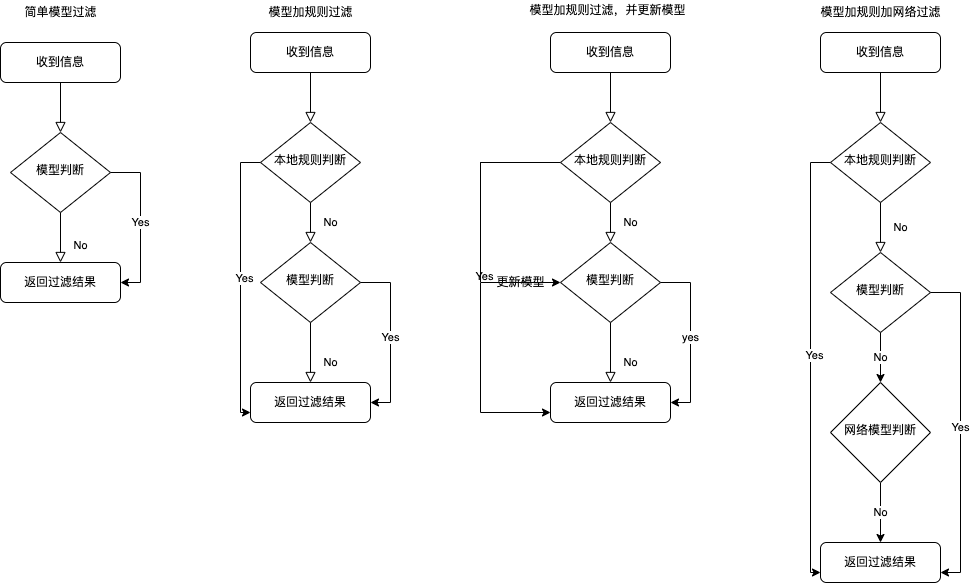
總結如下: