CreateML 使用#
背景#
業務需求,想要通過拍照識別照片中指定物體的數量或者物體的種類。而這種物體的模型網上沒有訓練好的,需要從頭開始。所以調研了蘋果的 createML 的實現方案,具體操作如下:
需求是:通過拍照識別照片中指定物體的數量,實現方案大致有幾種:
- 通過第三方平台,訓練數據,生成模型,提供前端使用
- 自己搭建平台,訓練數據,生成模型,提供前端使用
- 通過蘋果的 CreateML 工具,訓練數據,生成模型,供 iOS 使用或轉換成其他模型使用
對比可以發現,通過蘋果的 CreateML 工具,可以省去搭建平台的過程。下面來看看怎麼使用 CreateML。
使用 CreateML 的整體流程是:
- 有大量的樣本
- 標註所有的樣本
- 用這些樣本訓練生成模型
- 驗證模型的識別率
- 測試模型效果
- 導出模型供使用
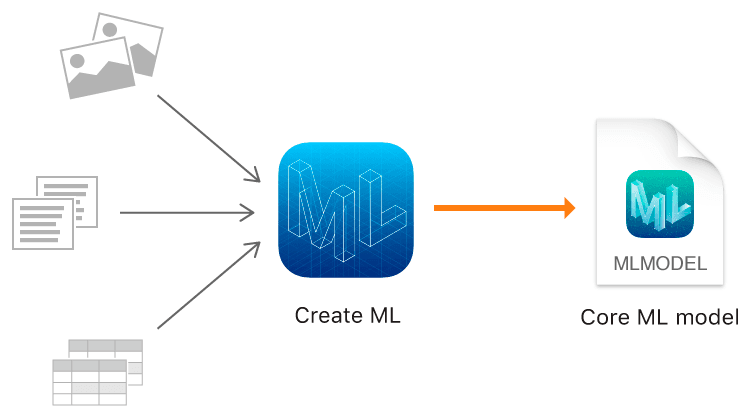
需求是通過拍照識別照片中指定物體的數量,所以對我來說樣本就是照片,下面就來看下怎麼生成 CreateML 訓練需求的標註信息。
使用#
樣本照片標註#
首先要有大量的樣本照片,這裡由於是調研測試,所以選取 20 張照片,照片來源是百度圖片。。。麻煩的是照片標註,由於蘋果 CreateML 訓練需要指定格式的JSON文件,格式如下:
[
{
"image": "圖片名字.jpg",
"annotations": [
{
"label": "標籤名字",
"coordinates": {
"x": 133,
"y": 240.5,
"width": 113.5,
"height": 185
}
}
]
}
]
所以找一個能直接導出Create ML支持的JSON格式的標註工具尤其重要。這裡參考Object Detection with Create ML: images and dataset使用roboflow來進行標註,具體使用如下:
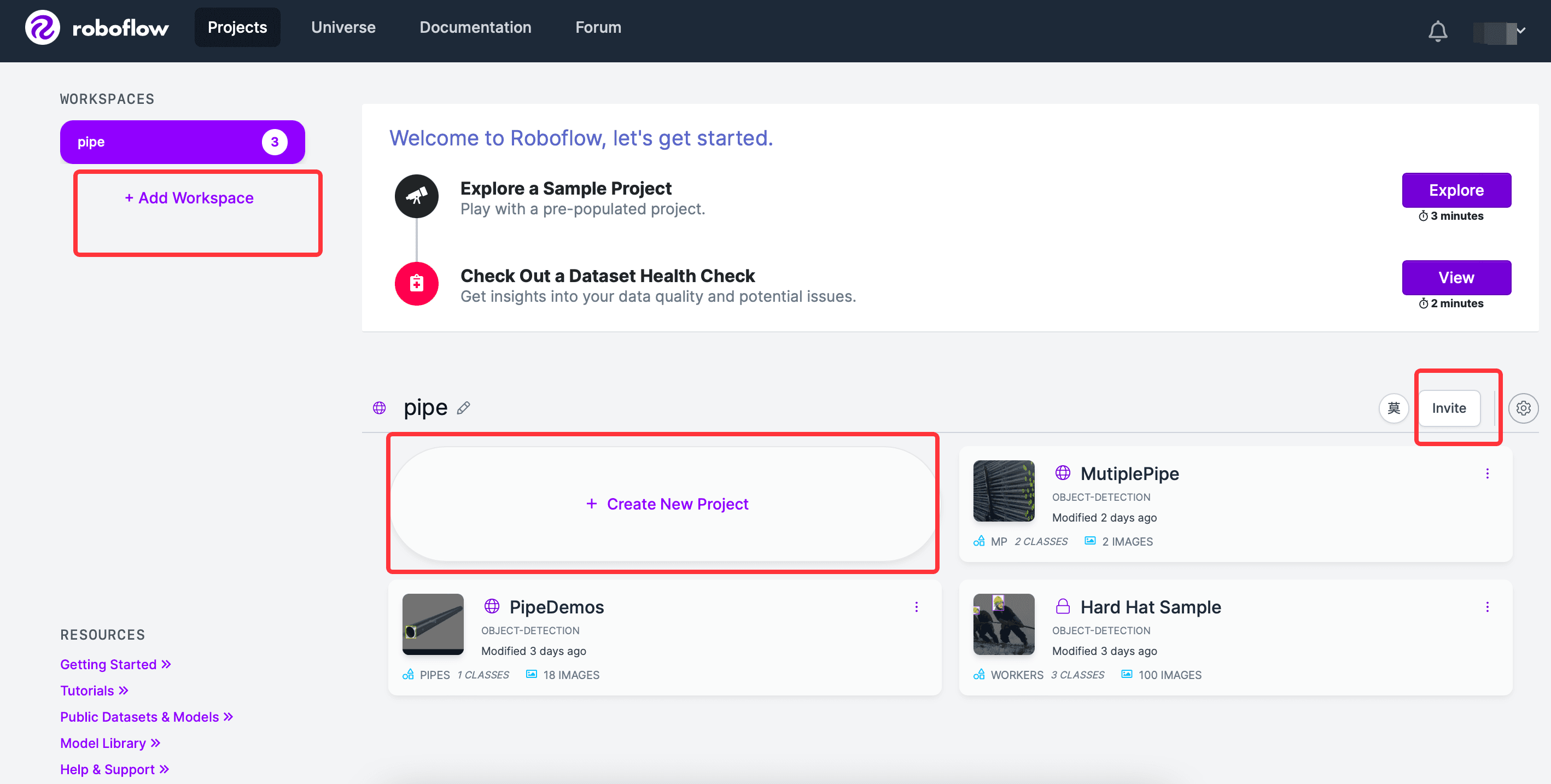
roboflow登錄後,會有引導步驟,建立 workSpace,workSpace 下新建項目,也可以邀請用戶加入到同一個 workSpace,界面如下:
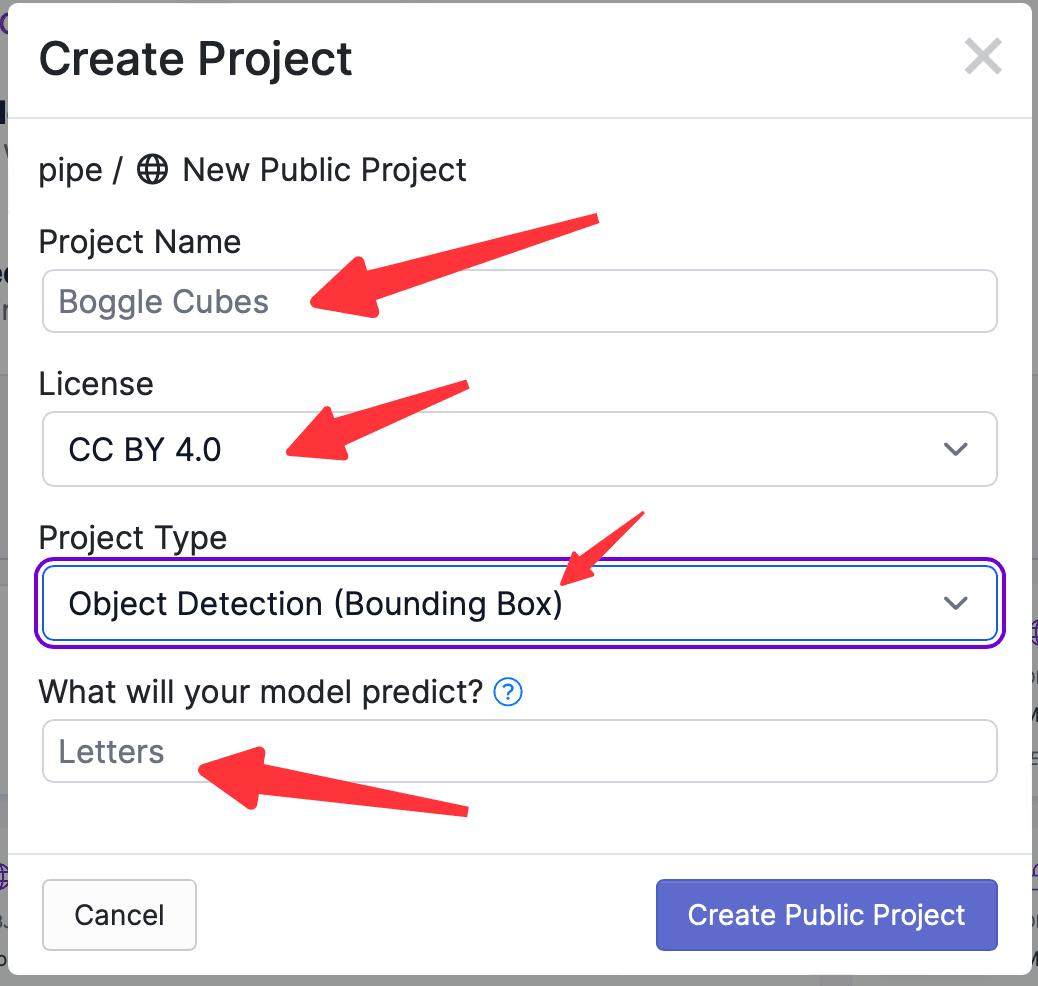
點擊Create Project,需要輸入項目的名字,選擇項目的License,選擇項目的功能,輸入要標記的物體的名字,界面如下:
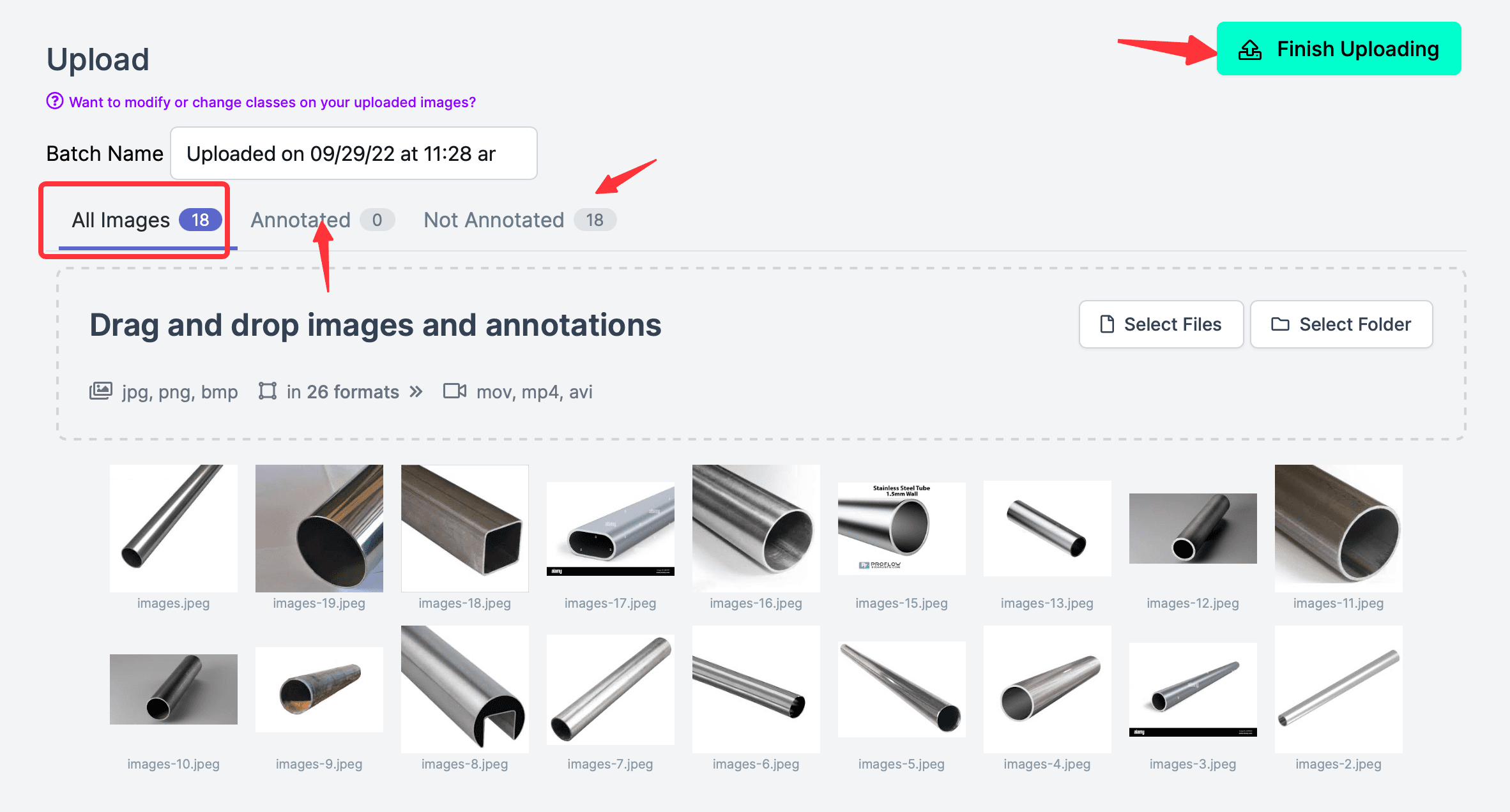
然後導入照片,比如去網上下載十幾張鋼管的照片,訓練識別鋼管(通常應該是很多很多照片,樣本越多,訓練出的模型就越準確這裡只用於演示流程,所以選取的照片不多);注意照片上傳完成後,不要點擊右上角的Finish Uploading,因為此時還沒有標註,注意All Images(18),Annotated(0),說明沒有一張標註的。
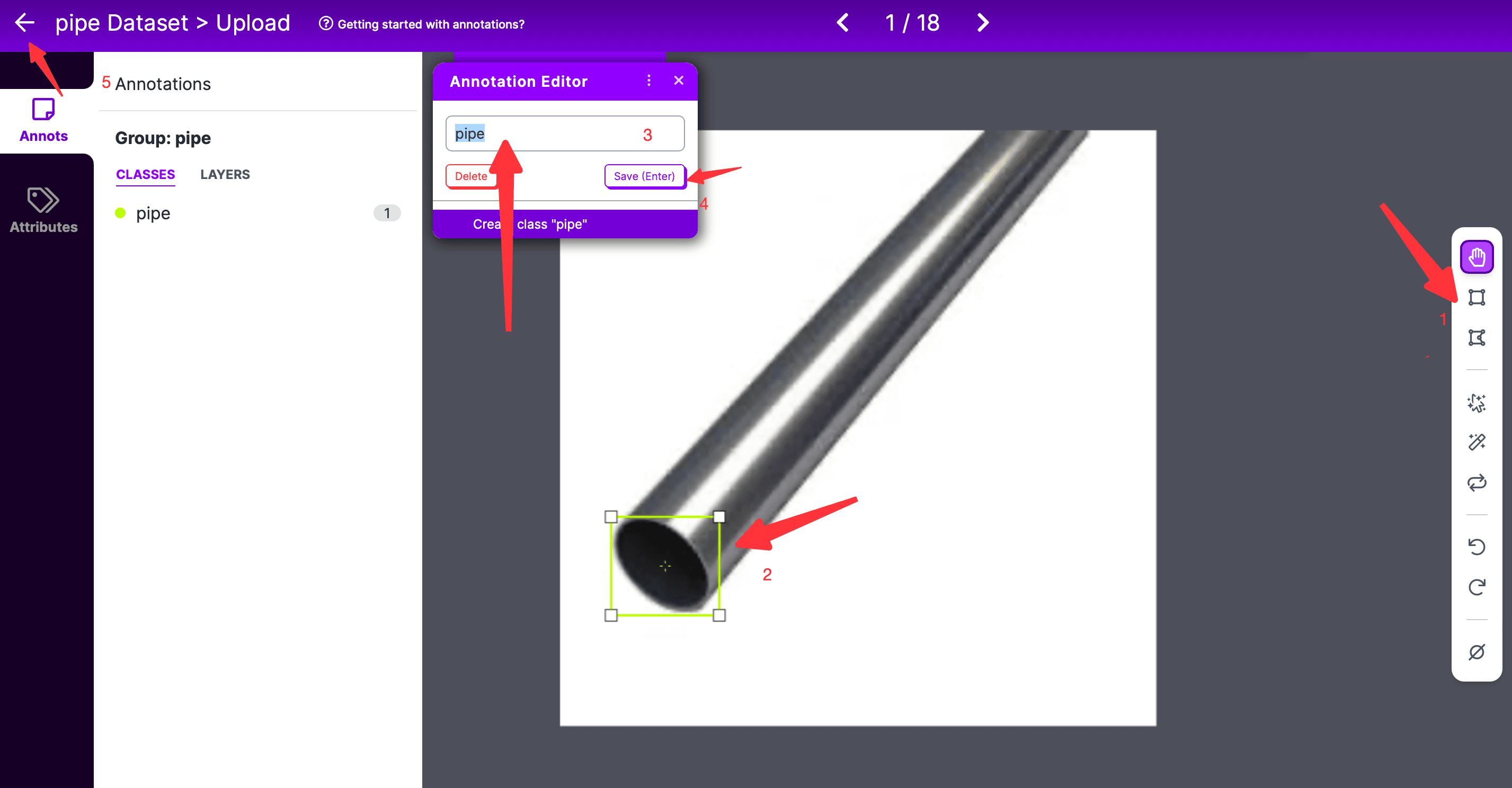
雙擊任意一張照片,即可進入標註頁面,
- 在標註頁面,要先選擇最右側標註工具,默認是長方形框框標註;
- 然後選擇標註的範圍,注意的是使用曲線標註時,起始和結束的兩個點要閉合;
- 然後在彈出的 Annotation Editor 框中,輸入要標記的 label,然後點擊保存;
- 如果有多個標記,則重複上面的過程;
- 所有標記都完成後,點擊左側的返回即可;
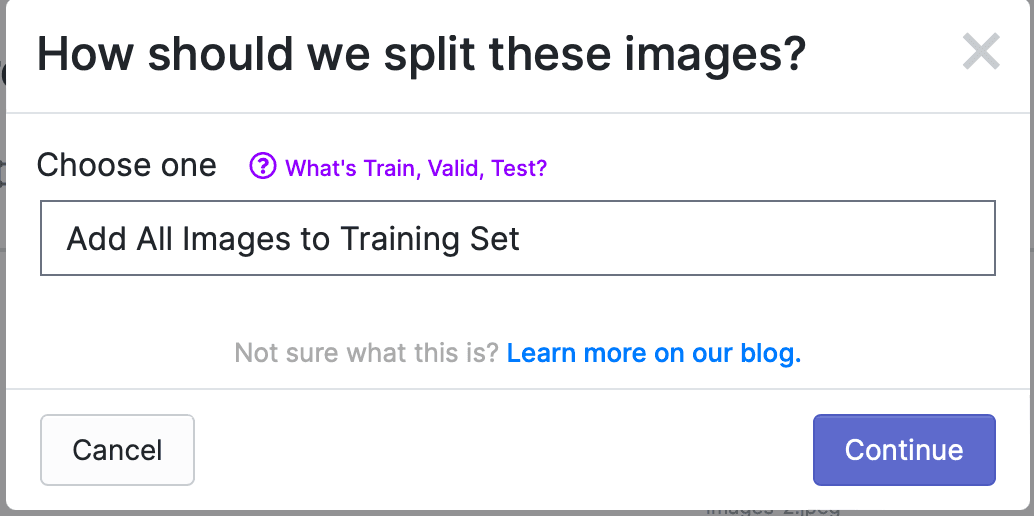
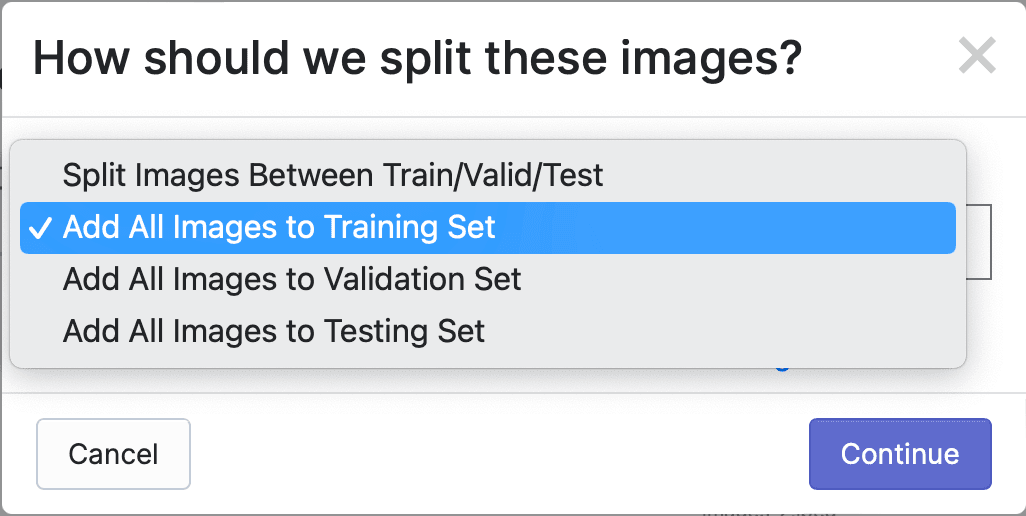
所有照片都標記好之後,點擊 Finish Uploading,會彈出如下提示框,選擇如何分配照片給Train、Valid和Test,默認是所有照片都用於Train,如下:
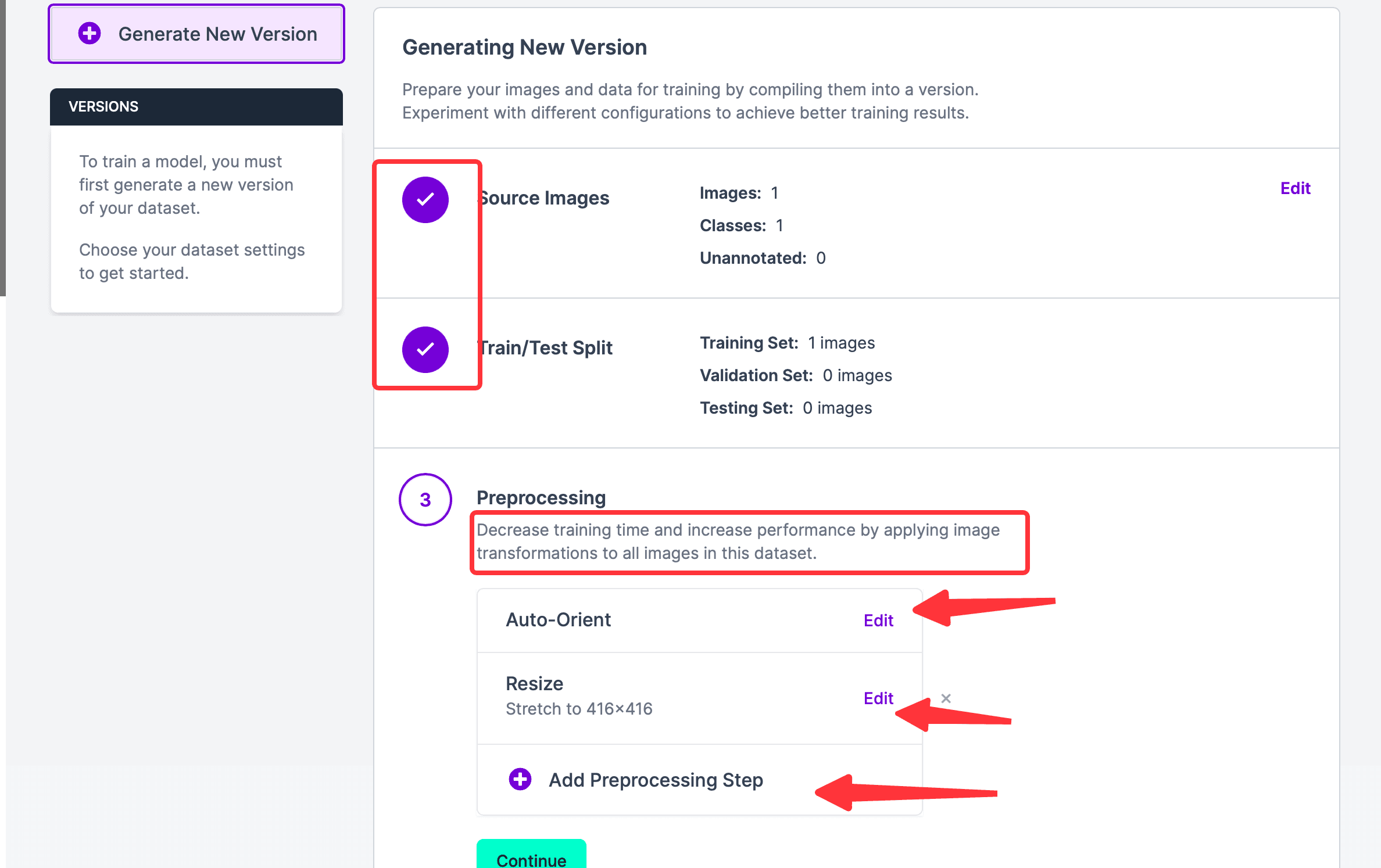
點擊 Continue,進入下一步。可以看到步驟 1 和 2 都已完成,如果想要編輯上面兩個步驟,也可以移動鼠標到對應模塊的右半邊,會出現編輯按鈕;目前所在步驟 3,Auto-Orient意思是Discard EXIF rotations and standardize pixel ordering.,如果不需要可以刪除這步;Resize是把照片重新調整大小。也可以添加Preprosession Step。這個步驟的預處理的目的是用於節省最終訓練時間。
點擊 Continue,進入步驟 4,這個步驟的目的是通過生成訓練集中每個圖像的增強版本,為模型創建新的訓練示例以進行學習。如果不需要,可以直接點擊 Continue,進入下一步。
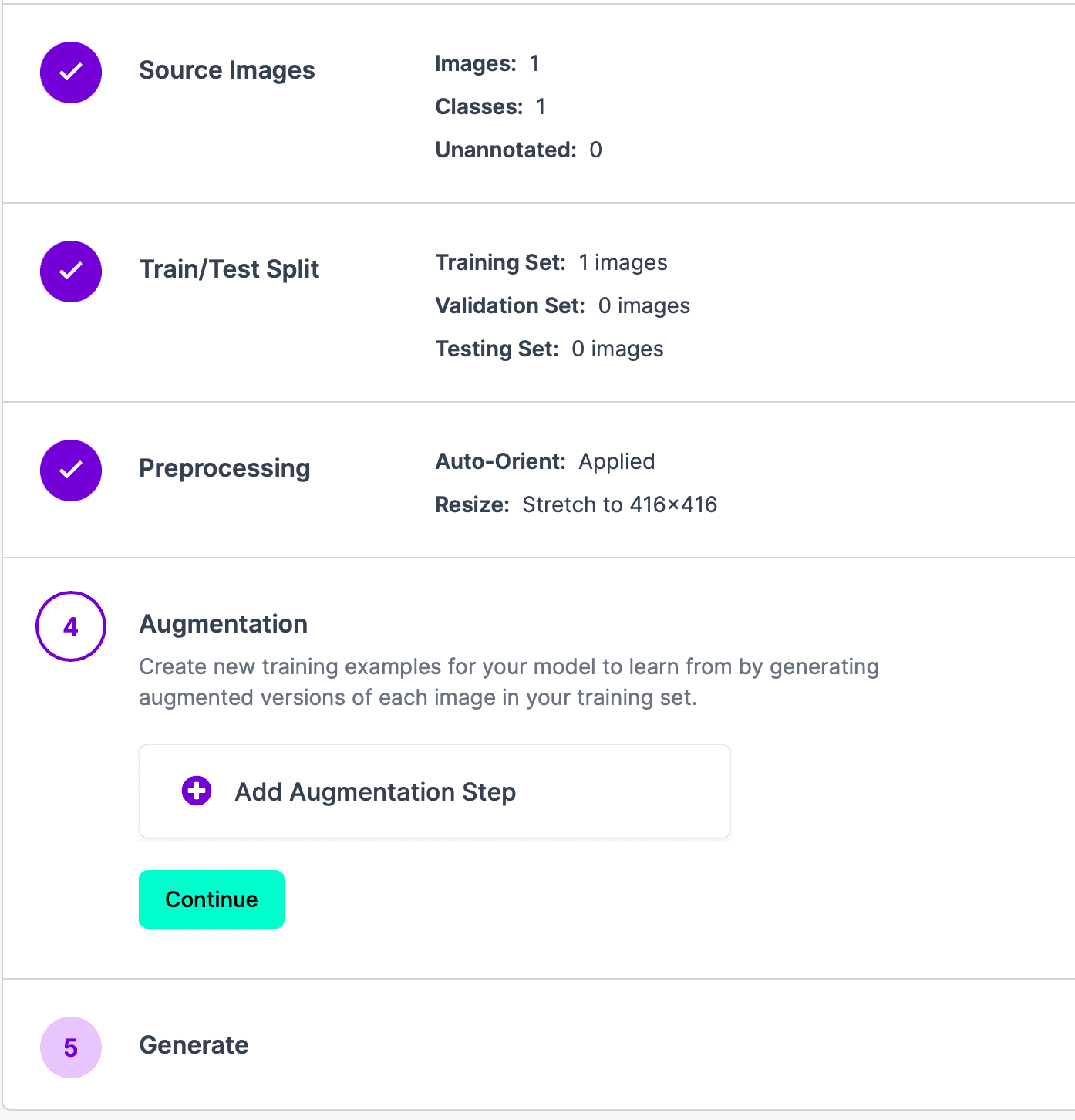
最後一步,就是生成結果,點擊 Generate,然後等待結果出現。結果如下:
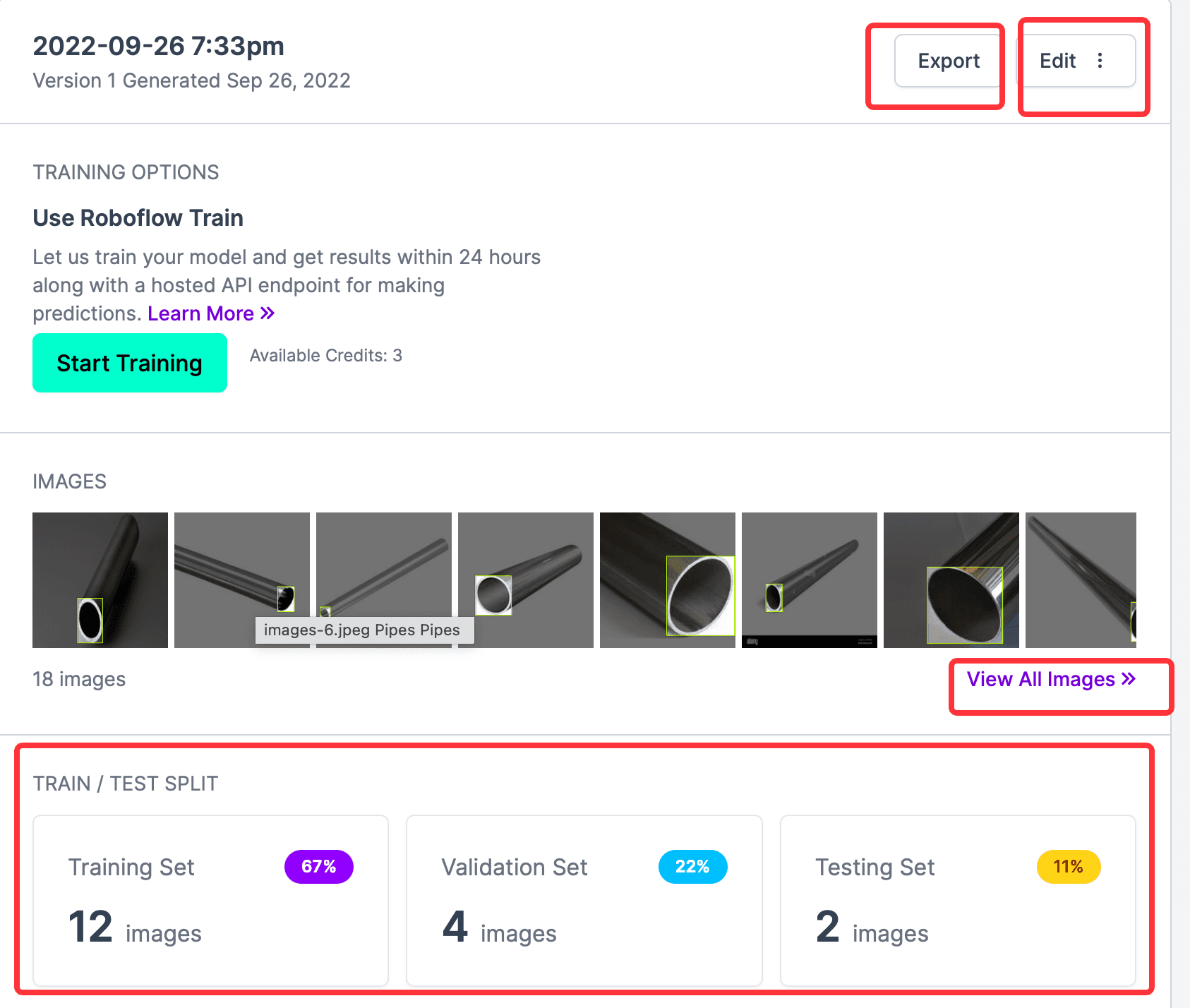
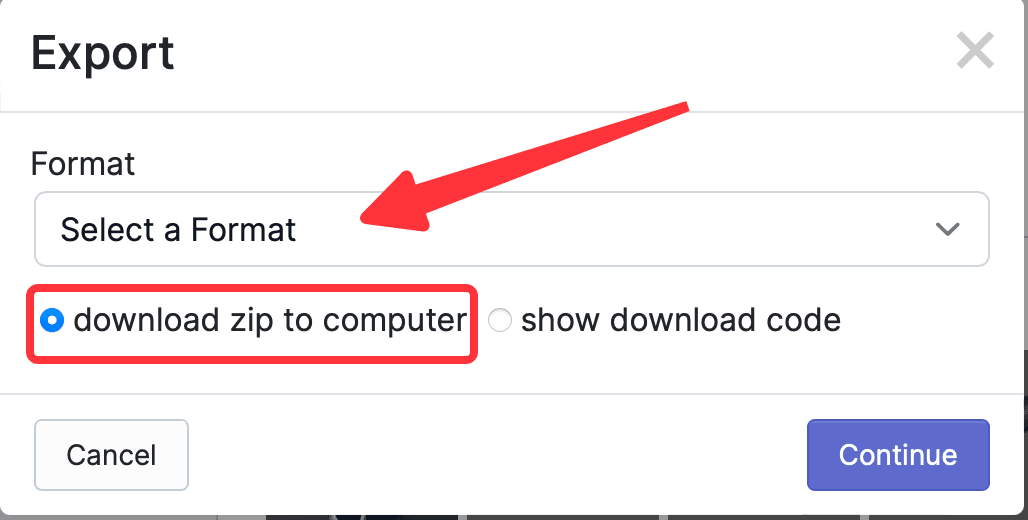
從上圖可以看到,所有標註的照片、Train和Validation和Test的數量,Start Training按鈕是網站提供的在線訓練功能,這裡用不到;需要的是導出 CreateML 類型的標註信息,所以點擊Export,在彈出的彈窗中選擇要導出的格式,這個網站最好用的就是導出支持的格式很多,這裡選擇CreateML,然後選中download zip to computer,點擊 Continue。
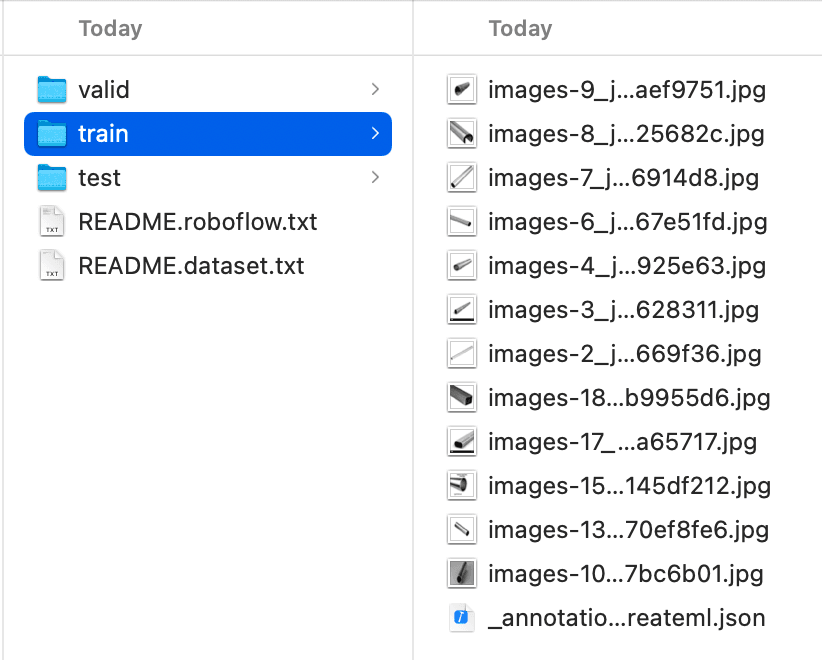
在 finder 中找到下載的xxx.createml.zip,解壓,查看文件夾,內容如下,可以看到Train、Valid、Test都已分類好,查看Train文件夾下_annotations.createml.json,可以看到格式和CreateML需要的一致,可以直接使用。
CreateML 使用#
選擇 Xcode -> Open Developer Tool -> Create ML,打開 CreateML 工具,如下:
然後進入選擇項目界面,如果已有 CreateML 項目,則選擇打開;沒有則選擇要保存的文件夾,然後點擊左下角的New Document進入創建頁面,創建頁面如下:
根據需要,選擇要創建的模板,這裡選擇Object Detection,然後輸入項目名字和描述,如下:
這裡歪個樓,看到
Text Classification和Word Tagging,想起來商店裡的短信過濾 APP,可能就是用大量的垃圾短信,然後通過 CreateML 訓練出模型,再導入到項目中,在項目中繼續用 Core ML 來不斷更新這個模型,從而針對每個人做到識別效果更好。
點擊下一步,進入主界面,如下圖所示,可以看到有以下幾部分:
- 上方中間的
Setting、Traning、Evaluation、Preview、Output代表 CreateML 的幾個步驟,可以切換查看,目前後面個步驟都是空的,因為還沒有訓練的結果。 - 上方左側的
Train按鈕是在中間部分TrainingData選擇導入數據後,開始訓練。 - Data 部分分別可以用剛剛下載的文件夾中的內容,但是首先要導入
Train的文件,並且等訓練結果出來後,可以繼續後面的步驟。 - Parameters 部分
- Algorithm 是選擇算法,默認的
FullNetworking是基於 YOLOv2 的,可以選擇TransferLearning,TransferLearning與樣本數量相關,訓練出的模型也更小。至於什麼是 YOLOv2,可以參考這篇文章A Gentle Introduction to Object Recognition With Deep Learning,看完會對深度學習的幾種算法有大致的理解 Iterations訓練的迭代次數,並不是越大越好,也不能太小。Batch Size,每次迭代訓練的數據大小,值越大佔用的內存越大。參考What is batch size in neural network?Grid Size,參考gridsize,YOLO 算法中分割圖片為多少塊。
- Algorithm 是選擇算法,默認的
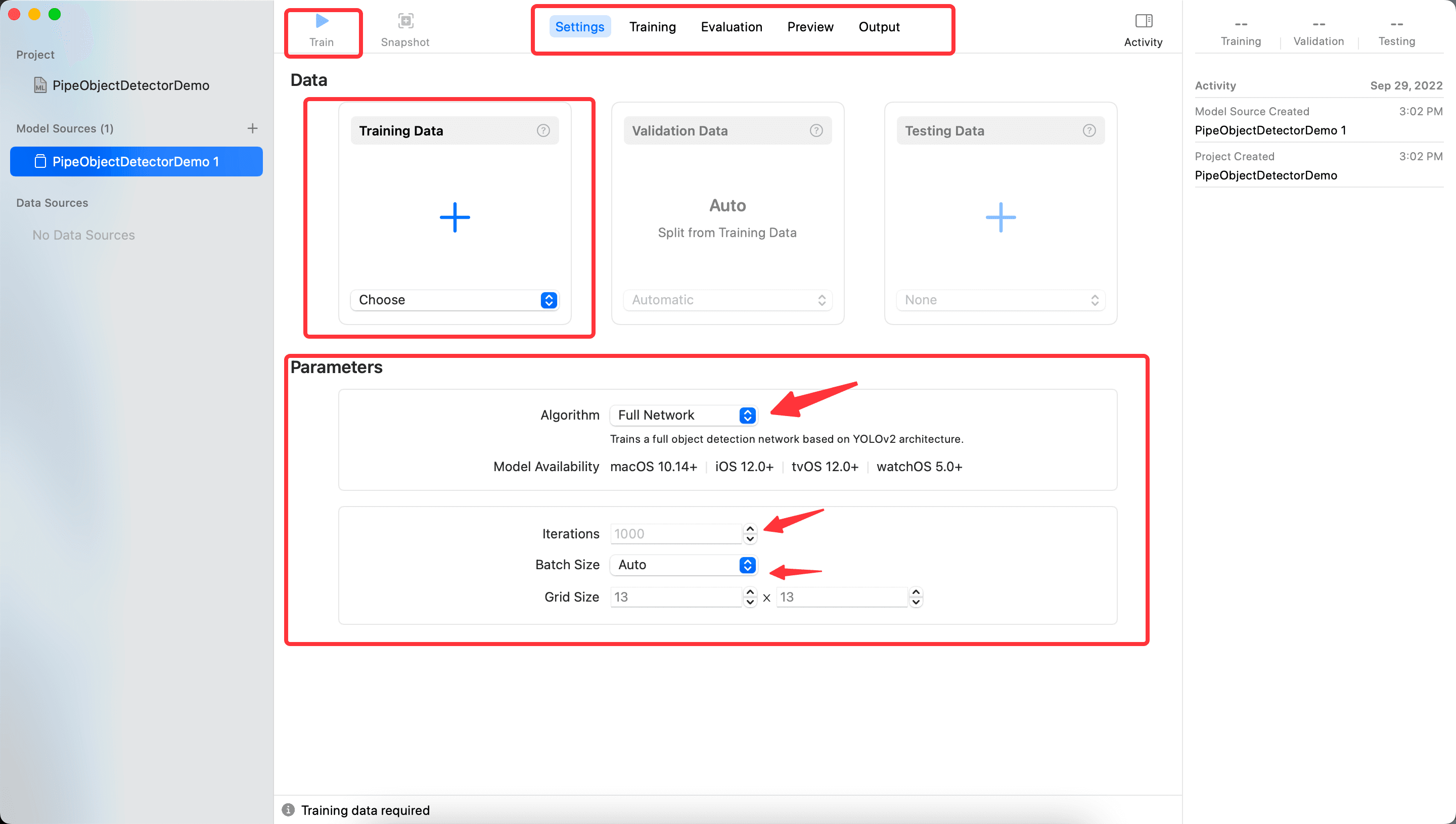
這裡設置 Iterations 為 100,其餘採用默認設置,然後點擊Train,會進入Training的步驟,最終結果如下:
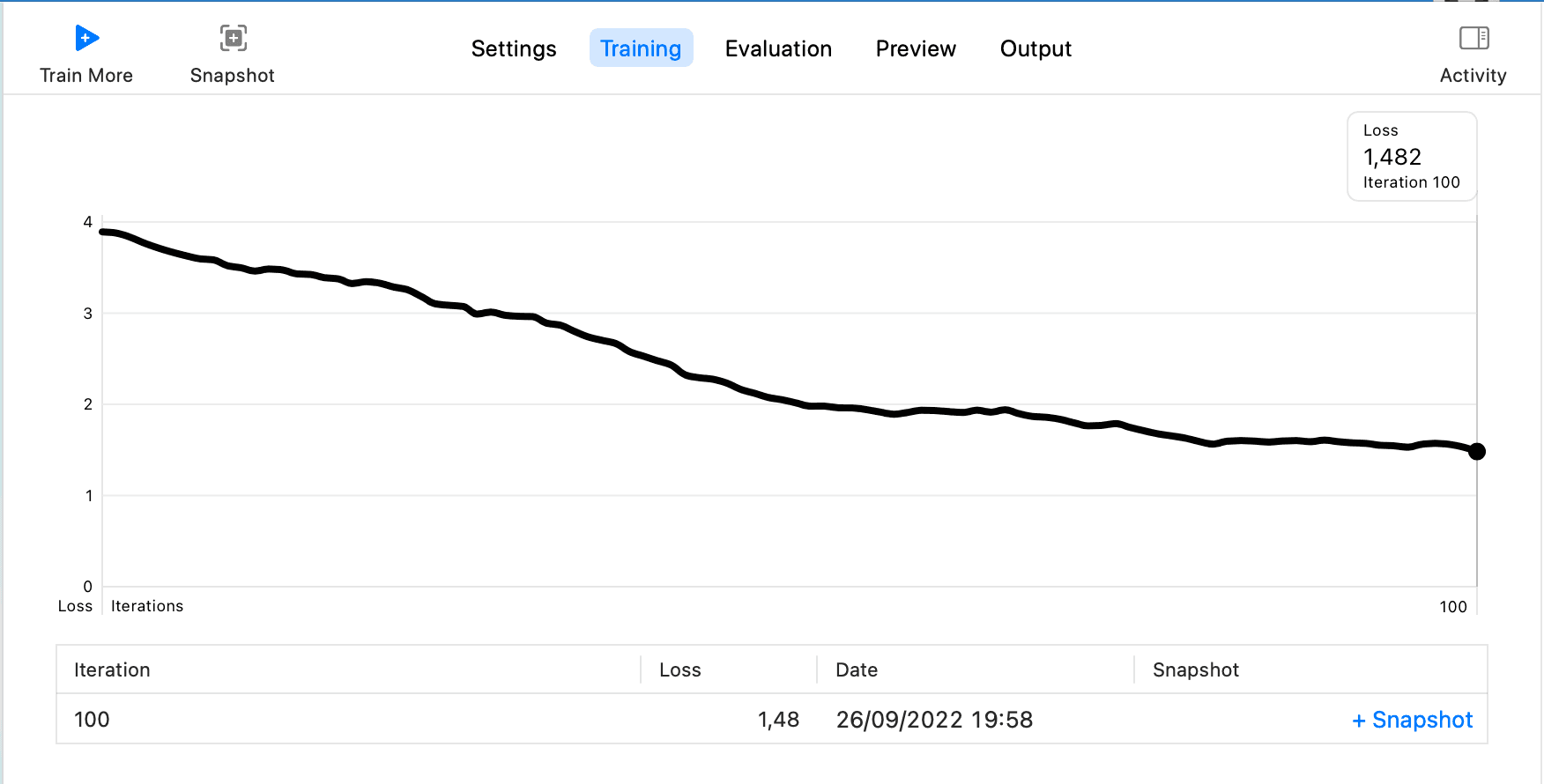
然後選擇Testing Data,由於下載的標註中Test只有兩條數據,所以可以接著用Train來作為Testing Data的數據,點擊Test,然後等待結果出現,如下:
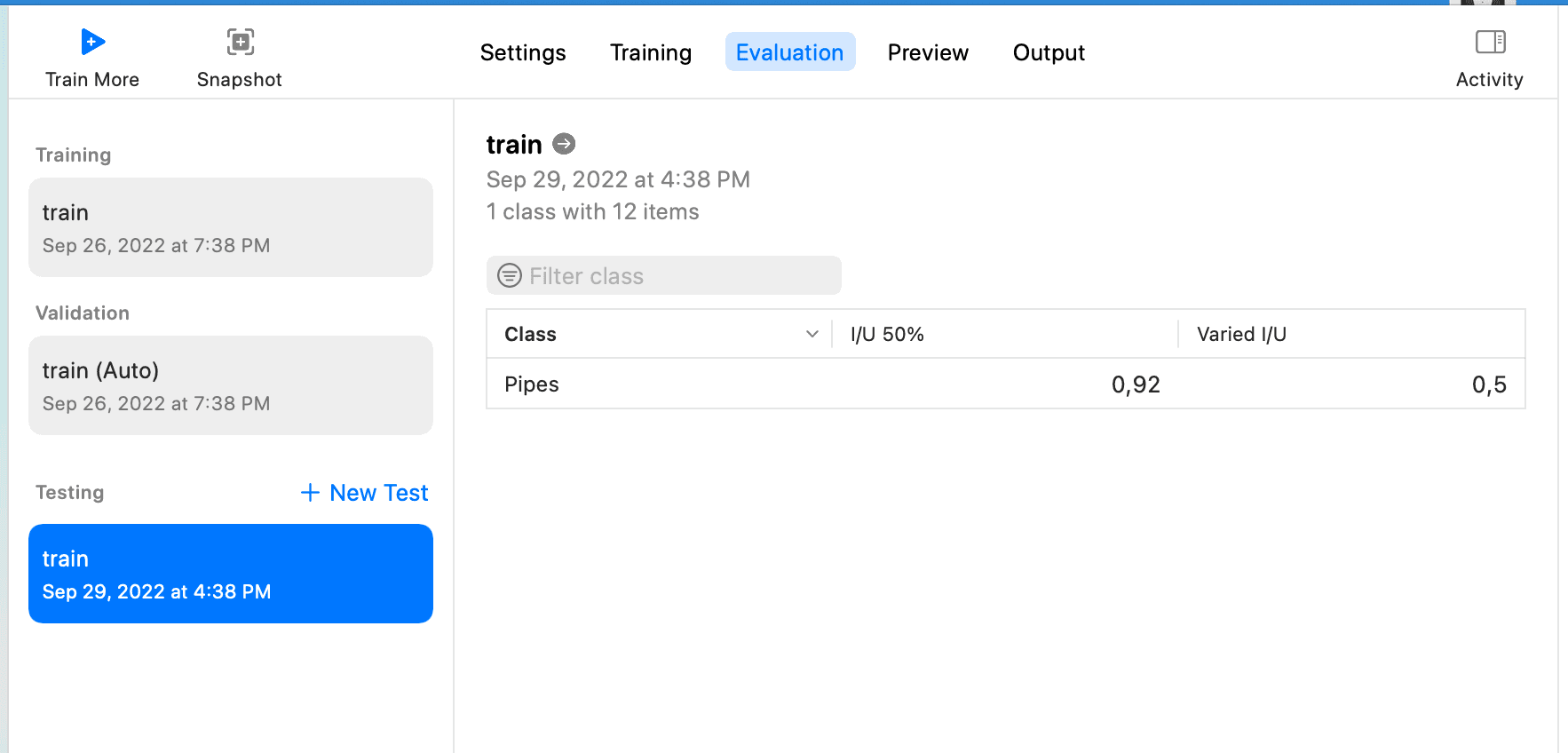
這個頁面上的I/U 50%和Varied I/U的意義可參考CreateML object detection evaluation
I/U means "Intersection over Union". It is a very simple metric which tells you how good the model is at predicting a bounding box of an object. You can read more about I/U in the "Intersection over Union (IoU) for object detection" article at PyImageSearch.
So:
I/U 50% means how many observations have their I/U score over 50%
Varied I/U is an average I/U score for a data set
也可以通過 Preview 更直觀的查看識別效果,如下,點擊添加文件,選擇所有鋼管照片
然後一張張查看,就可以看到每張能不能識別出
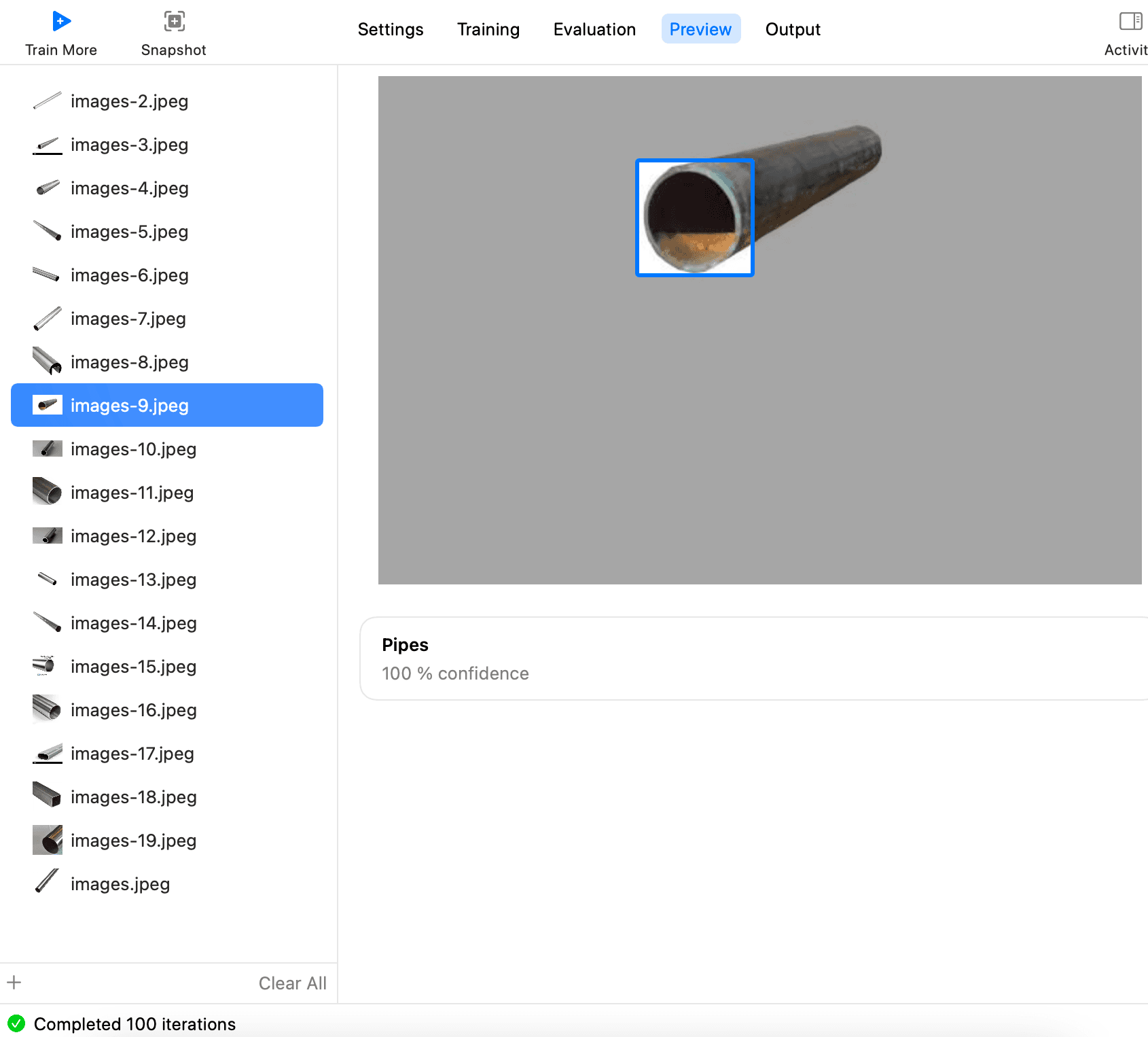
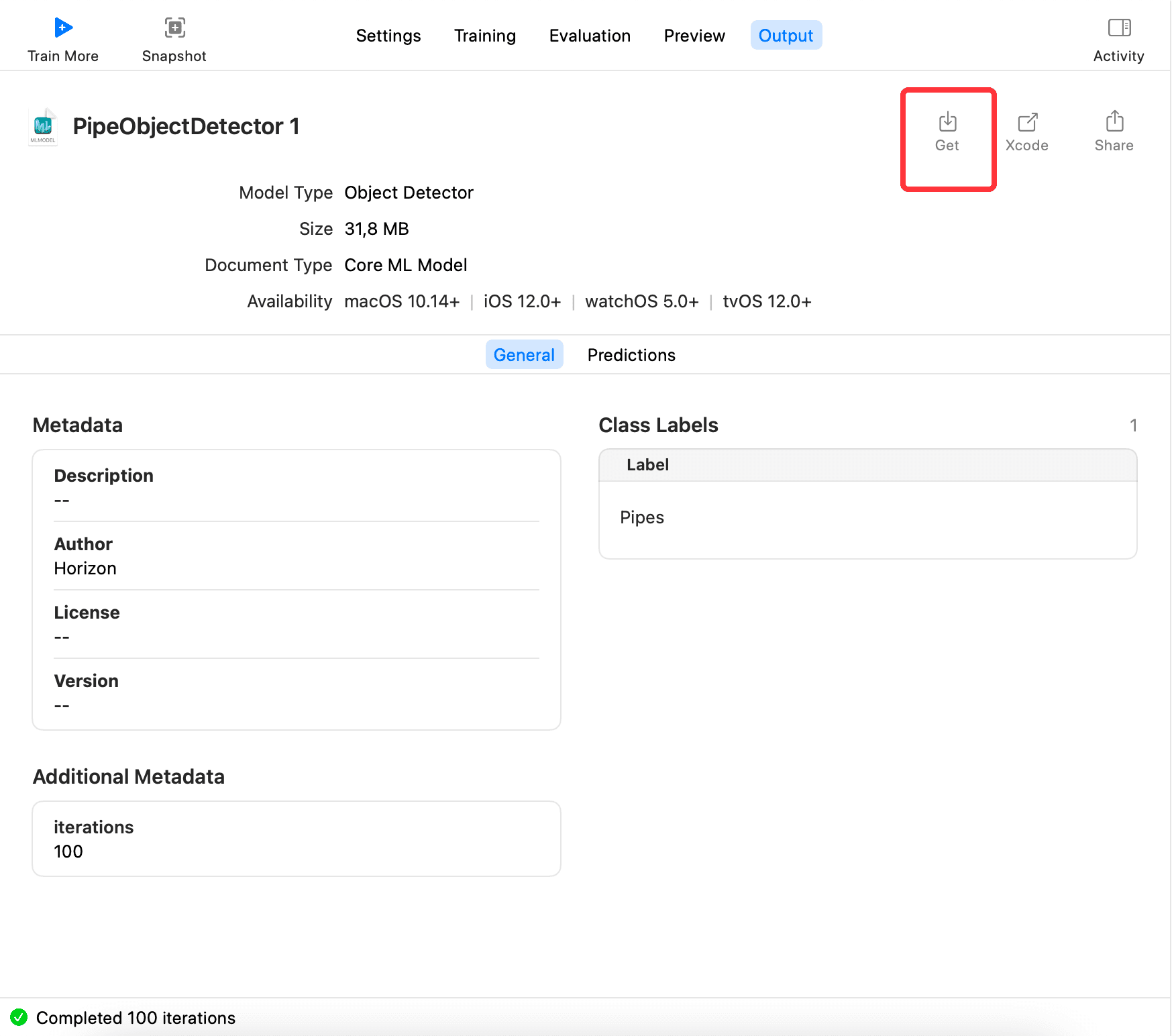
最後,切到 Output,點擊 Get,導出模型xxx.mlmodel,如下:
訓練出的模型 mlmodel 的使用#
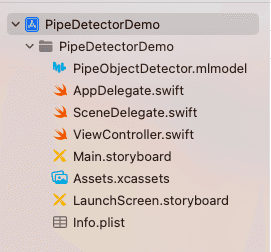
新建一個項目,把訓練出的模型導入到項目中,如下:
然後導入Vision庫,加載一張照片,然後生成VNImageRequestHandler,用生成的 handler 去識別,代碼如下:
class PipeImageDetectorVC: UIViewController {
// MARK: - properties
fileprivate var coreMLRequest: VNCoreMLRequest?
fileprivate var drawingBoxesView: DrawingBoxesView?
fileprivate var displayImageView: UIImageView = UIImageView()
fileprivate var randomLoadBtn: UIButton = UIButton(type: .custom)
// MARK: - view life cycle
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
setupDisplayImageView()
setupCoreMLRequest()
setupBoxesView()
setupRandomLoadBtn()
}
override func viewWillAppear(_ animated: Bool) {
super.viewWillAppear(animated)
}
// MARK: - init
fileprivate func setupDisplayImageView() {
view.addSubview(displayImageView)
displayImageView.contentMode = .scaleAspectFit
displayImageView.snp.makeConstraints { make in
make.center.equalTo(view.snp.center)
}
}
fileprivate func setupCoreMLRequest() {
guard let model = try? PipeObjectDetector(configuration: MLModelConfiguration()).model,
let visionModel = try? VNCoreMLModel(for: model) else {
return
}
coreMLRequest = VNCoreMLRequest(model: visionModel, completionHandler: { [weak self] (request, error) in
self?.handleVMRequestDidComplete(request, error: error)
})
coreMLRequest?.imageCropAndScaleOption = .centerCrop
}
fileprivate func setupBoxesView() {
let drawingBoxesView = DrawingBoxesView()
drawingBoxesView.frame = displayImageView.frame
displayImageView.addSubview(drawingBoxesView)
drawingBoxesView.snp.makeConstraints { make in
make.edges.equalToSuperview()
}
self.drawingBoxesView = drawingBoxesView
}
fileprivate func setupRandomLoadBtn() {
randomLoadBtn.setTitle("隨機加載一張圖片", for: .normal)
randomLoadBtn.setTitleColor(UIColor.blue, for: .normal)
view.addSubview(randomLoadBtn)
let screenW = UIScreen.main.bounds.width
let screeH = UIScreen.main.bounds.height
let btnH = 52.0
let btnW = 200.0
randomLoadBtn.frame = CGRect(x: (screenW - btnW) / 2.0, y: screeH - btnH - 10.0, width: btnW, height: btnH)
randomLoadBtn.addTarget(self, action: #selector(handleRandomLoad), for: .touchUpInside)
}
// MARK: - utils
// MARK: - action
fileprivate func handleVMRequestDidComplete(_ request: VNRequest, error: Error?) {
let results = request.results as? [VNRecognizedObjectObservation]
DispatchQueue.main.async {
if let prediction = results?.first {
self.drawingBoxesView?.drawBox(with: [prediction])
} else {
self.drawingBoxesView?.removeBox()
}
}
}
@objc fileprivate func handleRandomLoad() {
let imageName = randomImageName()
if let image = UIImage(named: imageName),
let cgImage = image.cgImage,
let request = coreMLRequest {
displayImageView.image = image
let handler = VNImageRequestHandler(cgImage: cgImage)
try? handler.perform([request])
}
}
// MARK: - other
fileprivate func randomImageName() -> String {
let maxNum: UInt32 = 18
let minNum: UInt32 = 1
let randomNum = arc4random_uniform(maxNum - minNum) + minNum
let imageName = "images-\(randomNum).jpeg"
return imageName
}
}
最終效果如下,完整代碼已放在 Github: CreateMLDemo

總結#
本篇介紹了CreateML的整體流程,從模型標註 ,到訓練生成模型,再到使用模型,希望大家能對CreateML有大致的了解。後面再來研究下,已導入項目中的模型,能否更新,如何更新?以及嘗試做自己的短信過濾 APP。
參考#
- Create ML
- Creating an Object Detection Machine Learning Model with Create ML
- Object Detection with Create ML: images and dataset
- Object Detection with Create ML: training and demo app
- On-device training with Core ML – part 1
- Core ML Explained: Apple's Machine Learning Framework
- A Gentle Introduction to Object Recognition With Deep Learning
- Turi Create