CreateML の使用#
背景#
ビジネスニーズとして、写真を撮影して指定した物体の数や種類を認識したいと考えています。しかし、そのような物体のモデルはオンラインでトレーニングされておらず、ゼロから始める必要があります。そこで、Apple の CreateML の実装方法を調査しました。具体的な操作は以下の通りです:
ニーズは:写真を撮影して指定した物体の数を認識することで、実現方法は大きく分けていくつかあります:
- サードパーティプラットフォームを通じて、データをトレーニングし、モデルを生成し、フロントエンドで使用する
- 自分でプラットフォームを構築し、データをトレーニングし、モデルを生成し、フロントエンドで使用する
- Apple の CreateML ツールを使用して、データをトレーニングし、モデルを生成し、iOS で使用するか、他のモデルに変換して使用する
比較すると、Apple の CreateML ツールを使用することで、プラットフォーム構築のプロセスを省略できます。では、CreateML の使用方法を見ていきましょう。
CreateML の全体的な流れは:
- 大量のサンプルがある
- すべてのサンプルにラベルを付ける
- これらのサンプルを使用してモデルをトレーニングする
- モデルの認識率を検証する
- モデルの効果をテストする
- 使用するためにモデルをエクスポートする
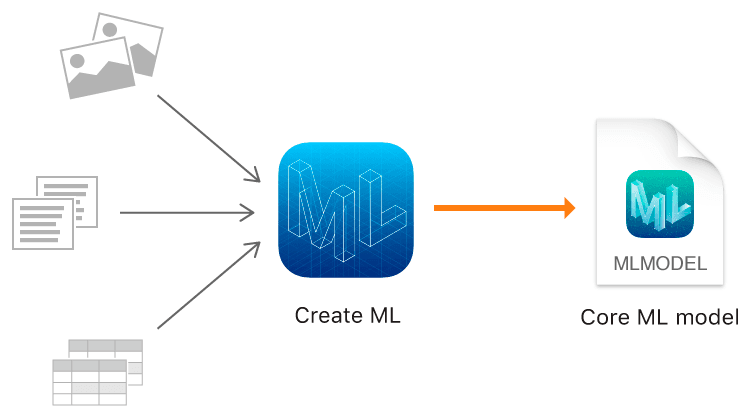
ニーズは写真を撮影して指定した物体の数を認識することであるため、私にとってのサンプルは写真です。次に、CreateML トレーニングのためのラベル情報を生成する方法を見ていきましょう。
使用#
サンプル写真のラベリング#
まず、大量のサンプル写真が必要です。ここでは調査テストのため、20 枚の写真を選択しました。写真の出所は百度画像です。。。面倒なのは写真のラベリングです。Apple の CreateML トレーニングには指定された形式のJSONファイルが必要で、形式は以下の通りです:
[
{
"image": "画像名.jpg",
"annotations": [
{
"label": "ラベル名",
"coordinates": {
"x": 133,
"y": 240.5,
"width": 113.5,
"height": 185
}
}
]
}
]
したがって、Create MLがサポートするJSON形式を直接エクスポートできるラベリングツールを見つけることが特に重要です。ここでは、Object Detection with Create ML: images and datasetを参考にして、roboflowを使用してラベリングを行います。具体的な使用方法は以下の通りです:
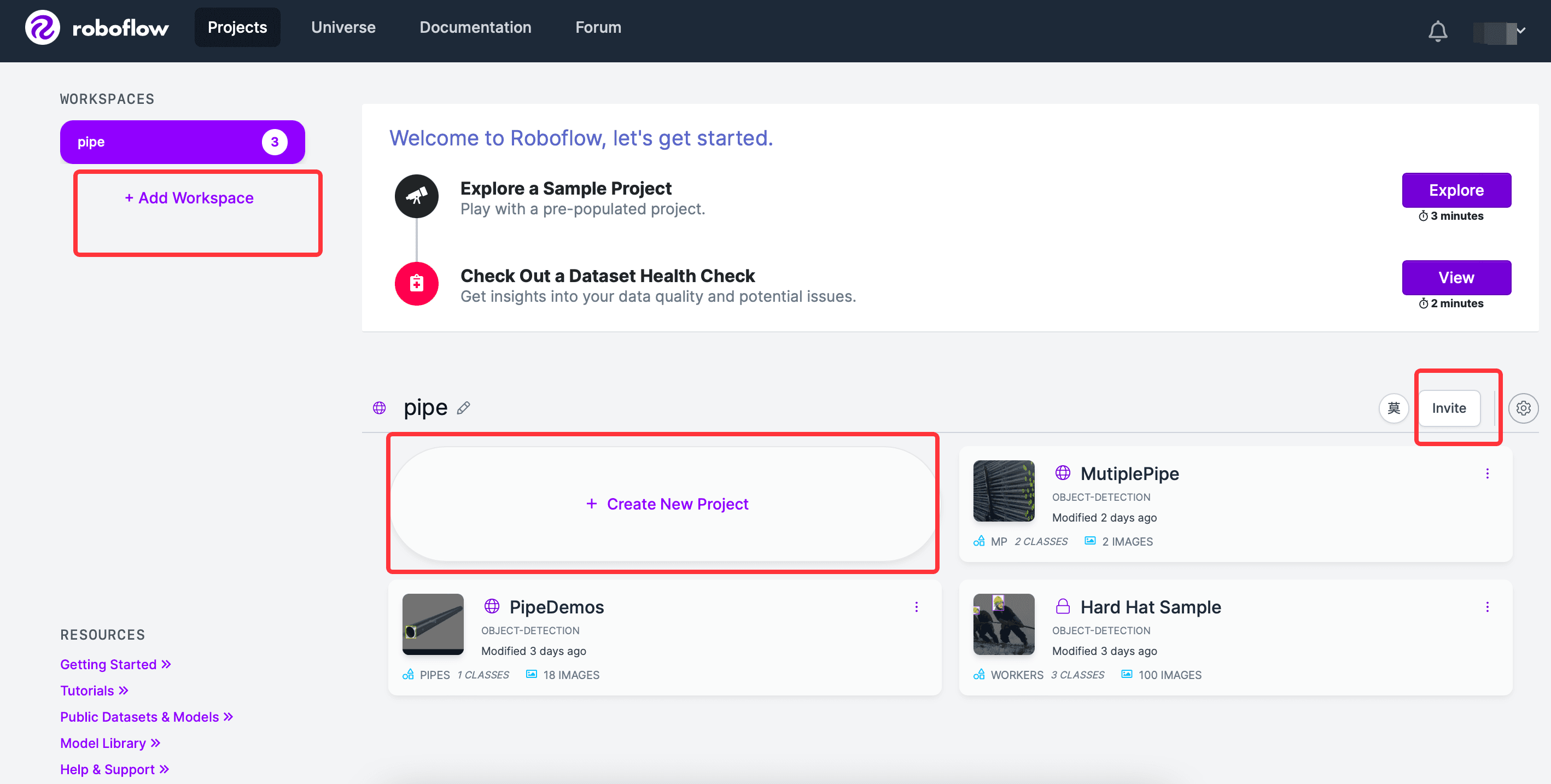
roboflowにログインすると、ガイド手順が表示され、ワークスペースを作成し、その下に新しいプロジェクトを作成できます。また、他のユーザーを同じワークスペースに招待することもできます。画面は以下の通りです:
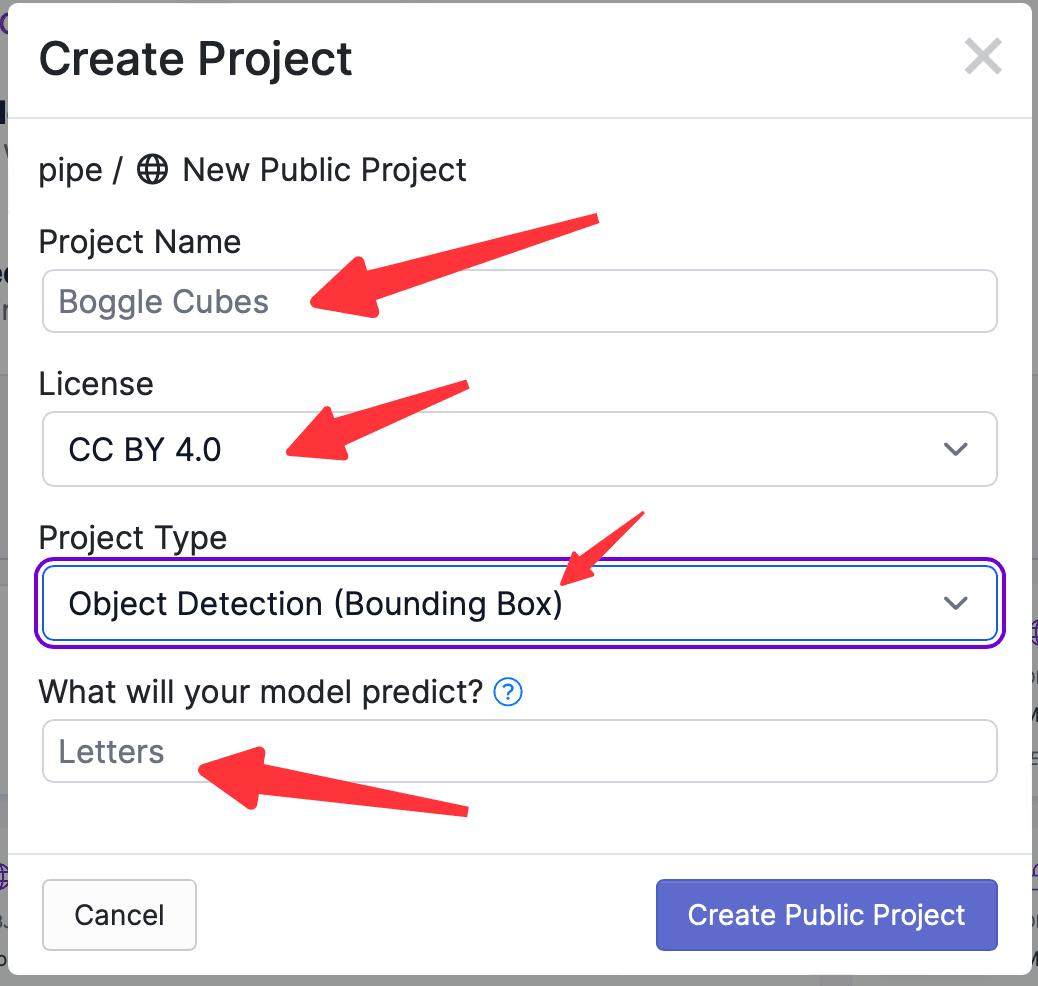
Create Projectをクリックし、プロジェクト名を入力し、プロジェクトのLicenseを選択し、プロジェクトの機能を選択し、ラベル付けする物体の名前を入力します。画面は以下の通りです:
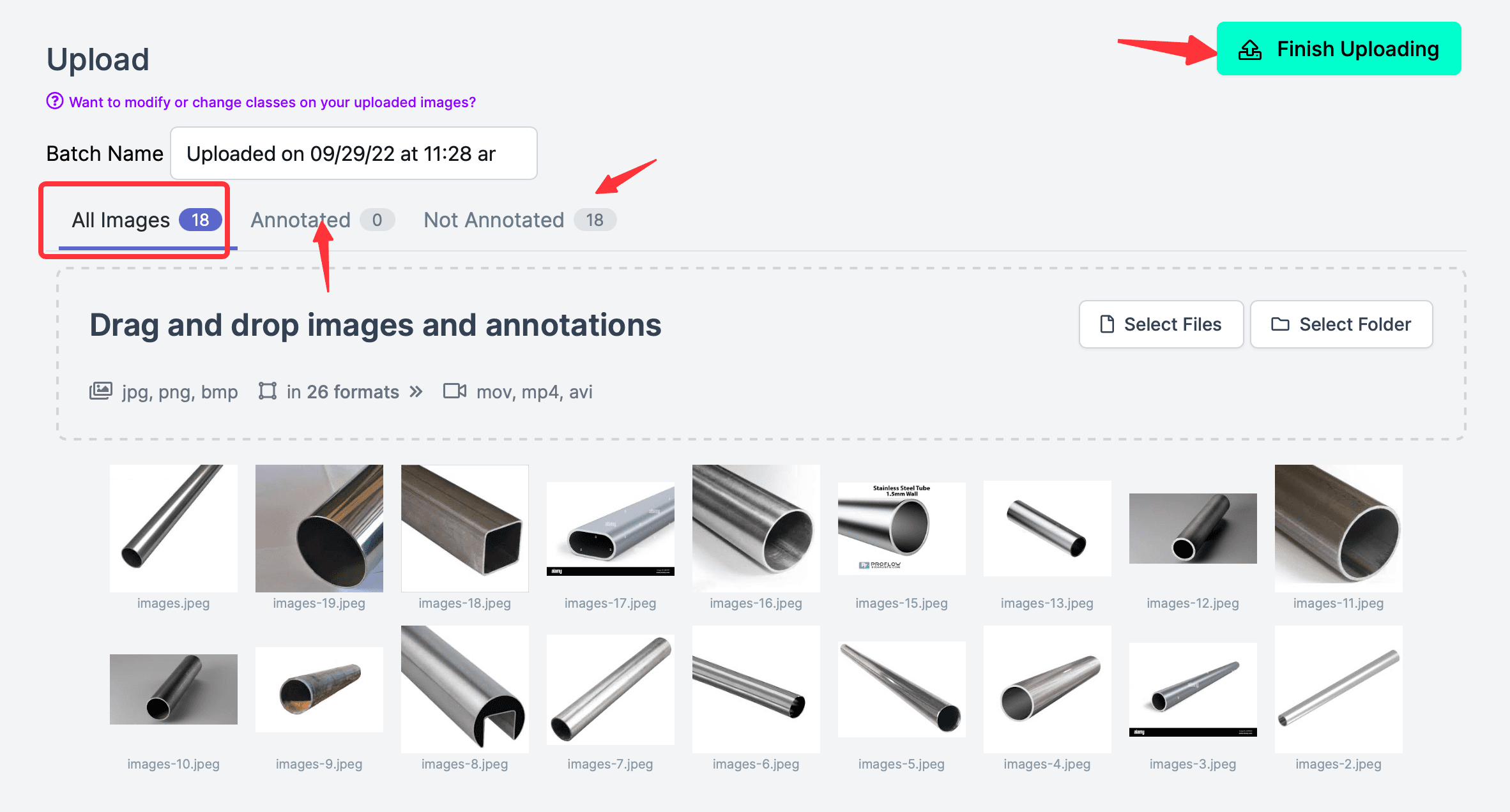
次に、写真をインポートします。例えば、インターネットから十数枚の鋼管の写真をダウンロードし、鋼管を認識するためにトレーニングします(通常は非常に多くの写真が必要で、サンプルが多いほどトレーニングされたモデルはより正確になりますが、ここではプロセスを示すために選択した写真は少ないです)。注意点として、写真のアップロードが完了した後、右上のFinish Uploadingをクリックしないでください。この時点ではまだラベリングが行われていないため、All Images(18)、Annotated(0)と表示され、ラベル付けされたものは一つもないことを示しています。
任意の写真をダブルクリックすると、ラベリングページに入ります。
- ラベリングページでは、最右側のラベリングツールを選択する必要があります。デフォルトは長方形のボックスラベリングです;
- 次に、ラベリングする範囲を選択します。曲線ラベリングを使用する場合は、開始点と終了点の 2 つの点を閉じる必要があります;
- その後、ポップアップの Annotation Editor ボックスにラベルを入力し、保存をクリックします;
- 複数のラベルがある場合は、上記のプロセスを繰り返します;
- すべてのラベル付けが完了したら、左側の戻るをクリックします;
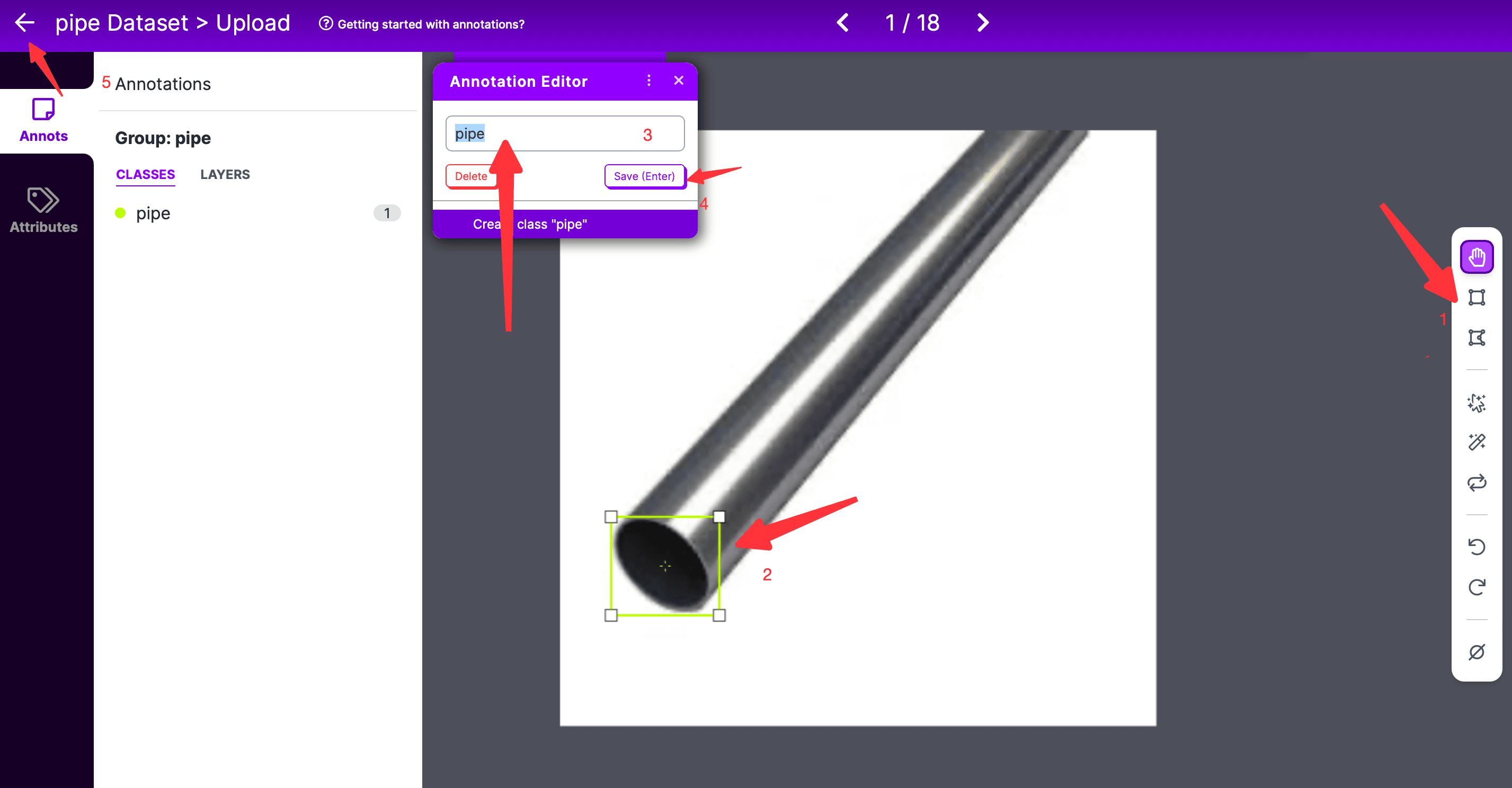
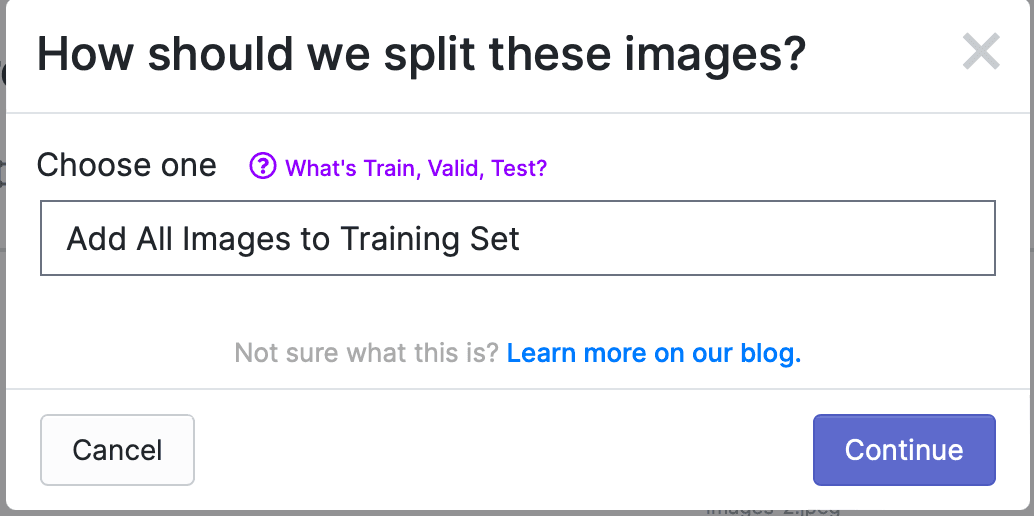
すべての写真にラベル付けが完了したら、Finish Uploadingをクリックします。以下のようなポップアップが表示され、写真をTrain、Valid、Testにどのように割り当てるかを選択します。デフォルトではすべての写真がTrainに使用されます。
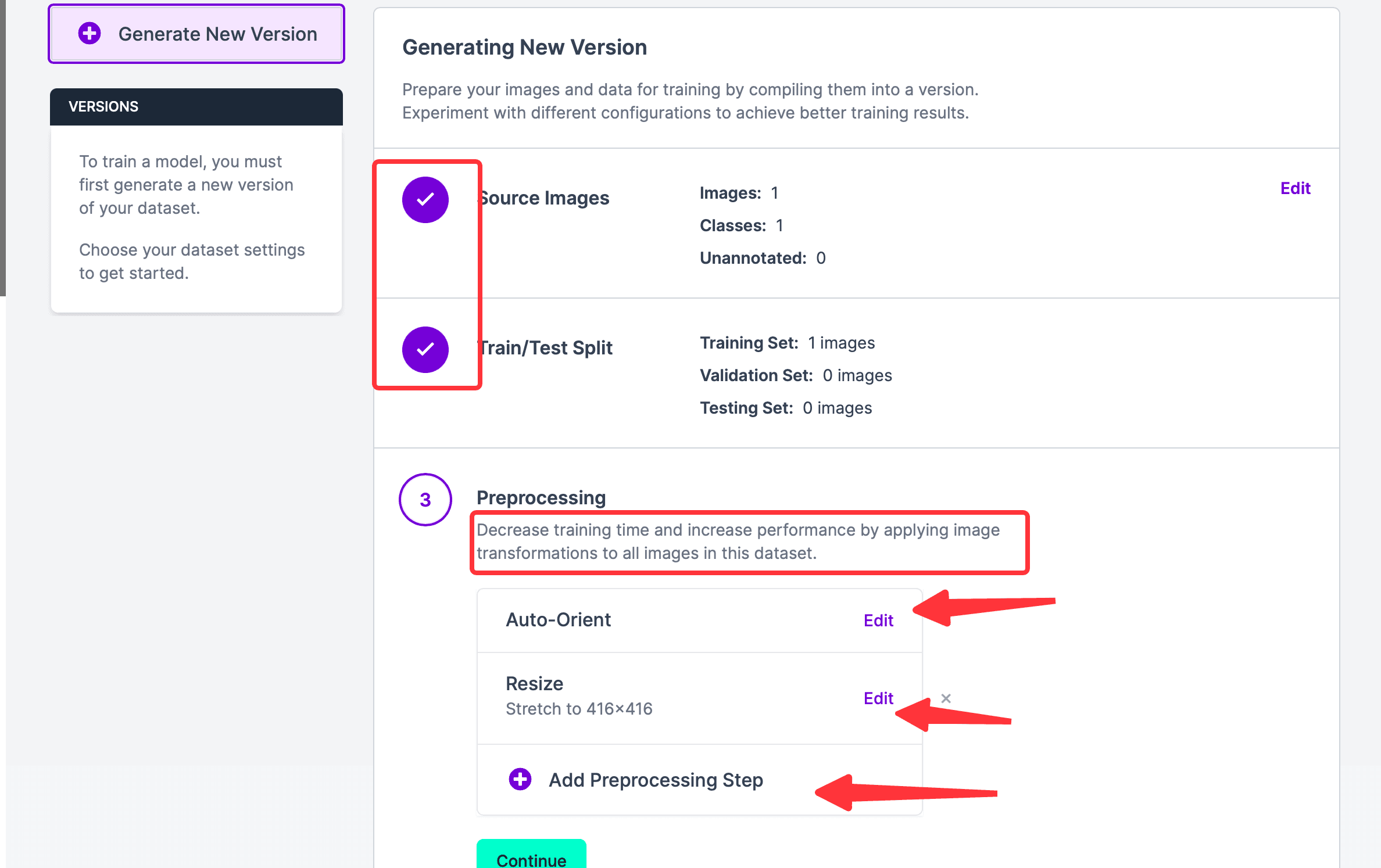
Continueをクリックして次のステップに進みます。ステップ 1 と 2 が完了したことが確認できます。上記の 2 つのステップを編集したい場合は、対応するモジュールの右側にマウスを移動すると、編集ボタンが表示されます。現在のステップ 3 では、Auto-OrientはEXIF回転を破棄し、ピクセルの順序を標準化するという意味です。必要ない場合はこのステップを削除できます;Resizeは写真のサイズを再調整します。Preprocessing Stepを追加することもできます。このステップの前処理の目的は、最終的なトレーニング時間を節約することです。
Continueをクリックしてステップ 4 に進みます。このステップの目的は、トレーニングセット内の各画像の強化バージョンを生成し、モデルに新しいトレーニングサンプルを学習させることです。必要ない場合は、直接Continueをクリックして次のステップに進みます。
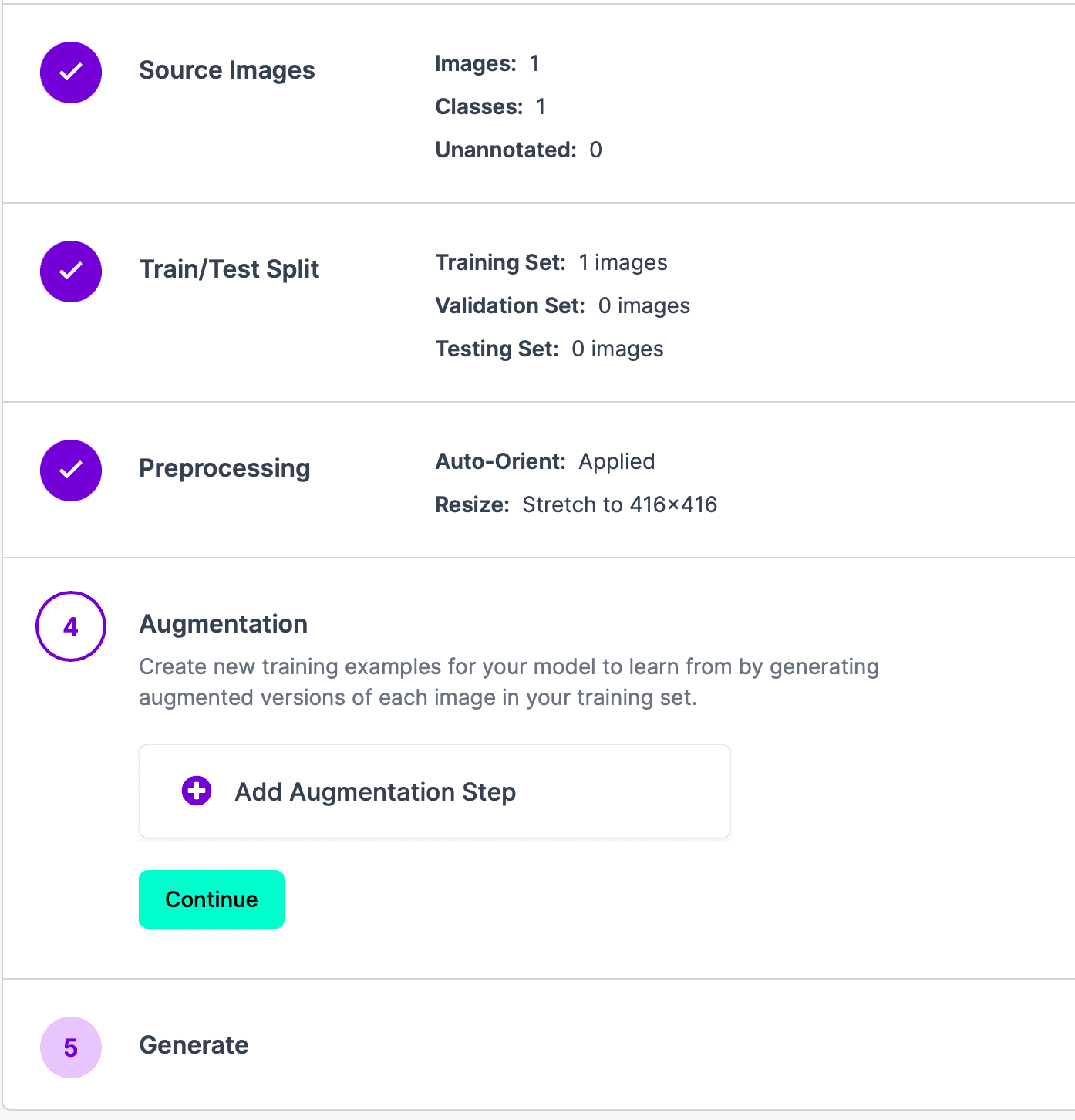
最後のステップは結果を生成することです。Generateをクリックし、結果が表示されるのを待ちます。結果は以下の通りです:
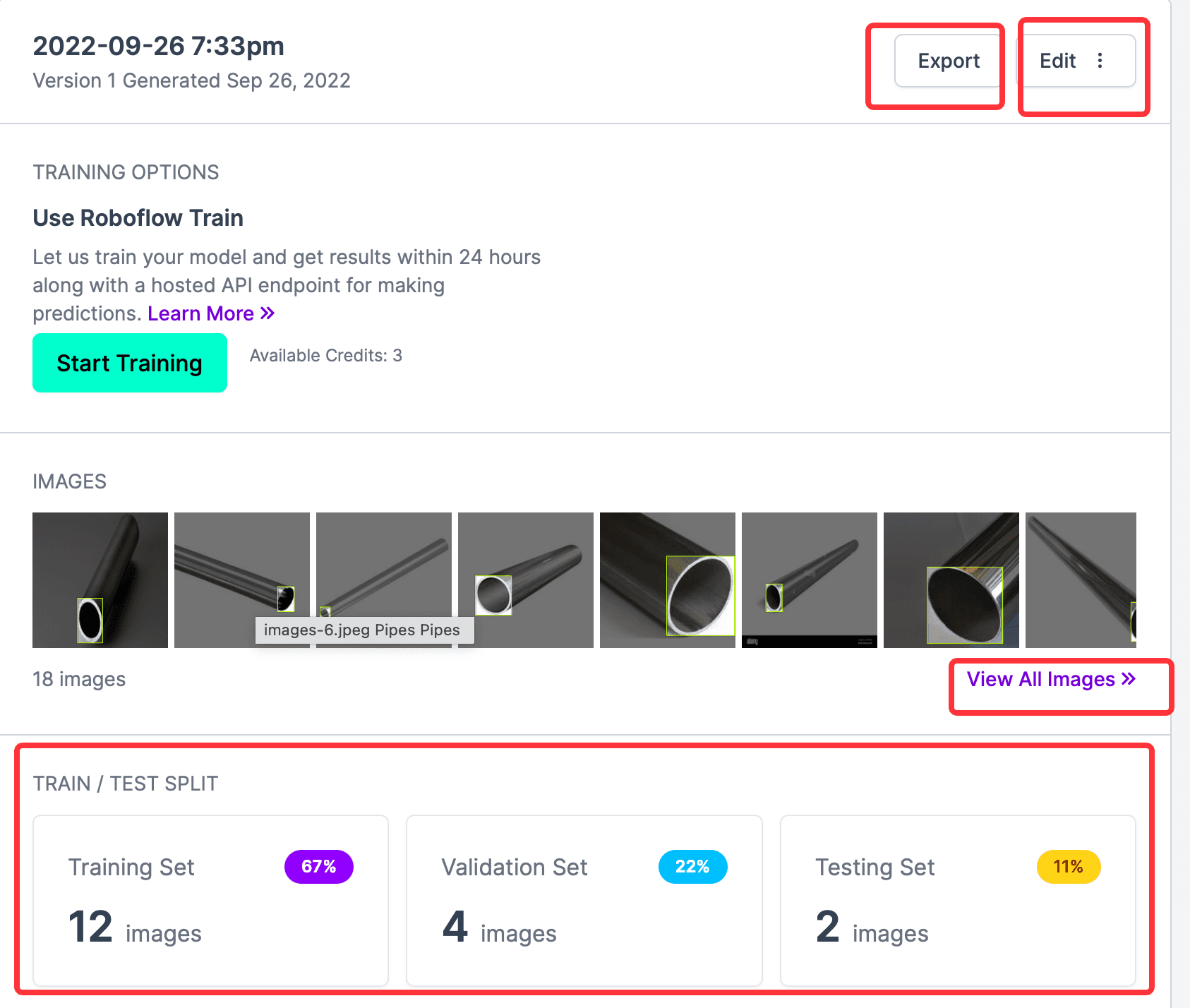
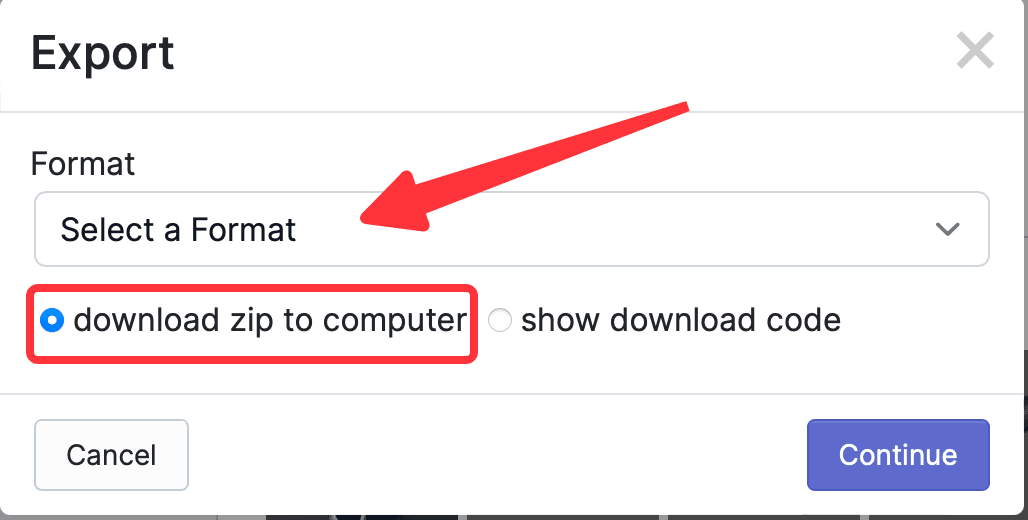
上の図から、すべてのラベル付けされた写真、Train、Validation、Testの数が確認できます。Start Trainingボタンはウェブサイトが提供するオンライントレーニング機能で、ここでは必要ありません。必要なのは CreateML タイプのラベル情報をエクスポートすることですので、Exportをクリックし、ポップアップウィンドウでエクスポートする形式を選択します。このウェブサイトはサポートされている形式が多く、最も便利です。ここではCreateMLを選択し、download zip to computerを選択してContinueをクリックします。
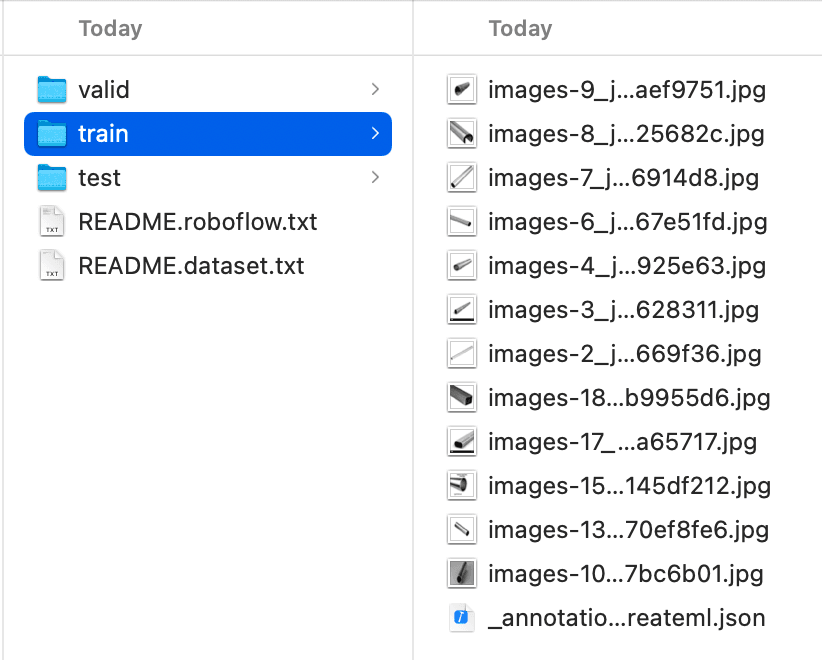
Finder でダウンロードしたxxx.createml.zipを見つけて解凍し、フォルダの内容を確認します。内容は以下の通りで、Train、Valid、Testがすでに分類されています。Trainフォルダ内の_annotations.createml.jsonを確認すると、形式がCreateMLの必要な形式と一致していることがわかり、そのまま使用できます。
CreateML の使用#
Xcode を選択 -> Open Developer Tool -> Create ML を選択し、CreateML ツールを開きます。以下のようになります:
次にプロジェクト選択画面に入ります。すでに CreateML プロジェクトがある場合はそれを選択し、ない場合は保存するフォルダを選択して左下のNew Documentをクリックして作成ページに入ります。作成ページは以下の通りです:
必要に応じて作成するテンプレートを選択します。ここではObject Detectionを選択し、プロジェクト名と説明を入力します。以下のようになります:
ここで少し脱線しますが、
Text ClassificationやWord Taggingを見て、店内の SMS フィルタリングアプリを思い出しました。おそらく大量の迷惑 SMS を使用して CreateML でモデルをトレーニングし、その後プロジェクトにインポートし、Core ML を使用してこのモデルを継続的に更新することで、各人に対してより良い認識効果を実現しているのでしょう。
次に進むと、メイン画面に入ります。以下の図のように、いくつかの部分が表示されます:
- 上部中央の
Setting、Training、Evaluation、Preview、Outputは CreateML のいくつかのステップを示しており、切り替えて表示できます。現在、後のステップはすべて空です。なぜなら、まだトレーニング結果がないからです。 - 上部左側の
Trainボタンは、中央のTrainingDataでデータをインポートした後にトレーニングを開始します。 - Data 部分は、先ほどダウンロードしたフォルダ内の内容を使用できますが、まず
Trainのファイルをインポートし、トレーニング結果が出た後に次のステップに進むことができます。 - Parameters 部分
- Algorithm はアルゴリズムを選択します。デフォルトの
FullNetworkingは YOLOv2 に基づいており、TransferLearningを選択することもできます。TransferLearningはサンプル数に関連しており、トレーニングされたモデルも小さくなります。YOLOv2 とは何かについては、A Gentle Introduction to Object Recognition With Deep Learningを参考にすると、深層学習のいくつかのアルゴリズムについて大まかな理解が得られます。 Iterationsはトレーニングの反復回数で、数が多いほど良いわけではなく、また少なすぎてもいけません。Batch Sizeは、各反復でトレーニングするデータのサイズで、値が大きいほどメモリを多く消費します。参考にWhat is batch size in neural network?Grid Sizeは、gridsizeを参考にし、YOLO アルゴリズムで画像を何ブロックに分割するかを示します。
- Algorithm はアルゴリズムを選択します。デフォルトの
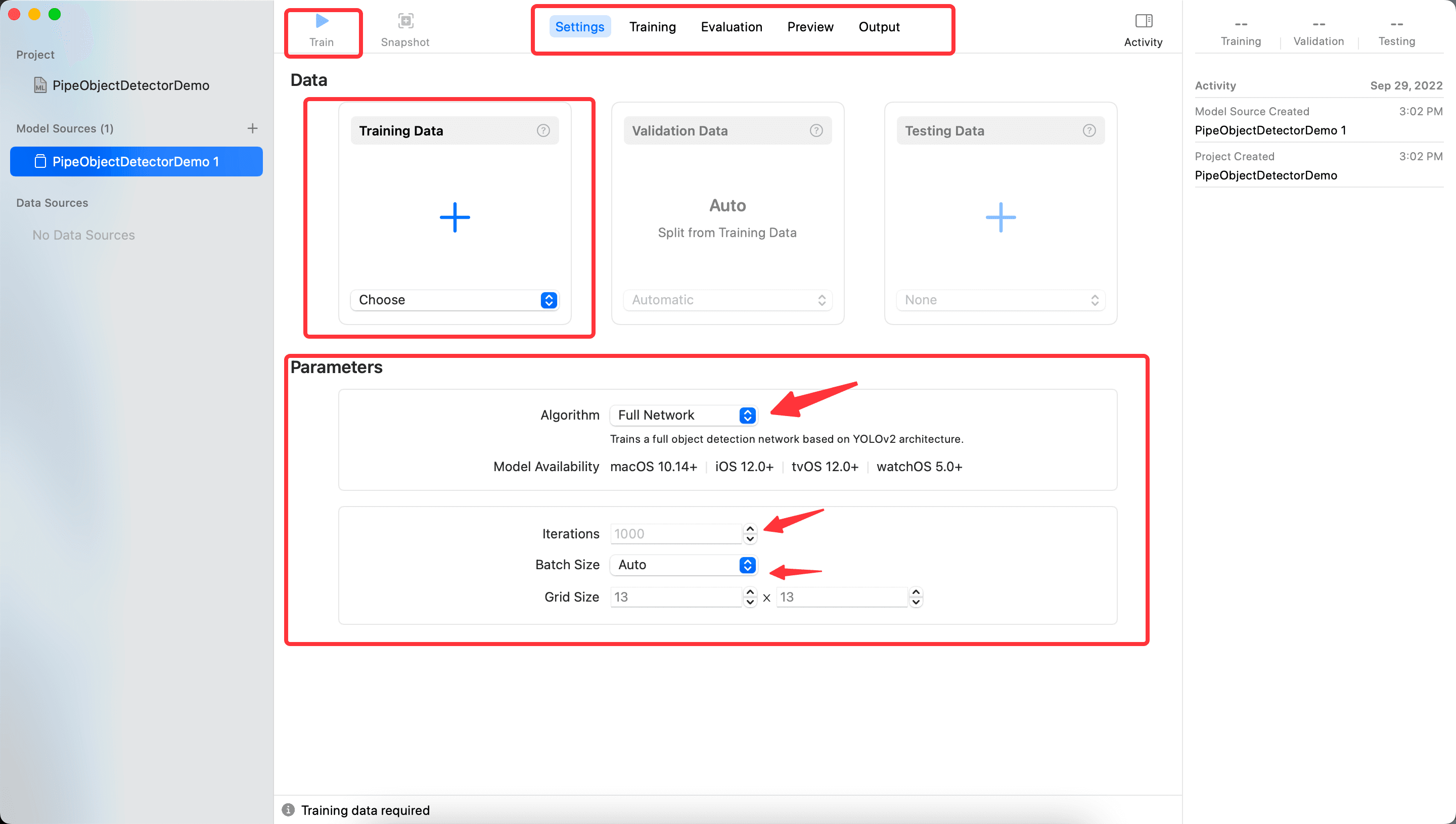
ここでは Iterations を 100 に設定し、他はデフォルト設定を使用してTrainをクリックします。Trainingのステップに入ります。最終結果は以下の通りです:
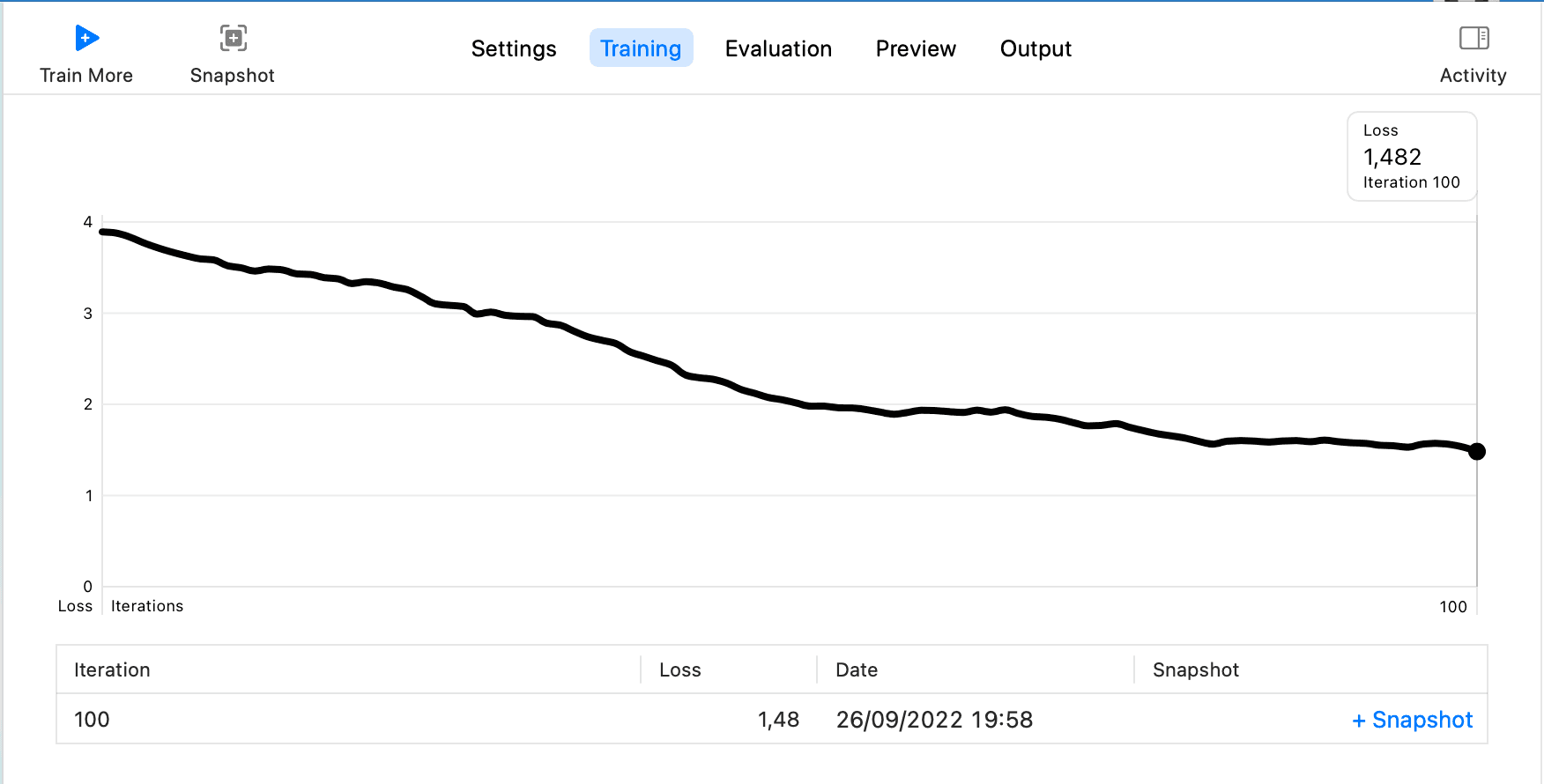
次にTesting Dataを選択します。ダウンロードしたラベルにTestが 2 つのデータしかないため、TrainをTesting Dataとして使用できます。Testをクリックし、結果が表示されるのを待ちます。以下のようになります:
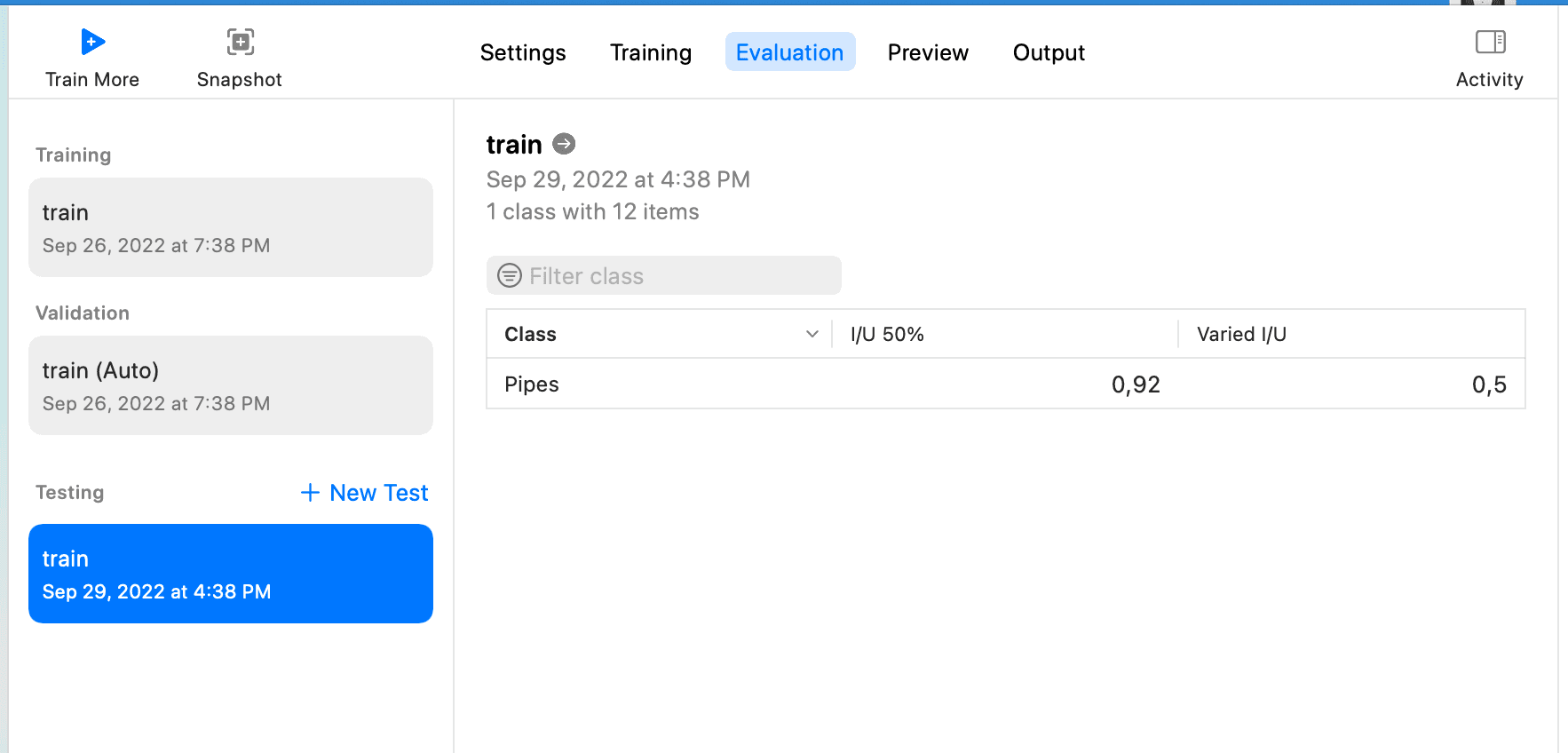
このページのI/U 50%とVaried I/Uの意味については、CreateML object detection evaluationを参考にしてください。
I/U は「Intersection over Union」を意味します。これは、モデルが物体のバウンディングボックスを予測する能力を示す非常にシンプルな指標です。I/U については、PyImageSearch の「Intersection over Union (IoU) for object detection」記事で詳しく読むことができます。
つまり:
I/U 50% は、I/U スコアが 50% を超える観測の数を示します。
Varied I/U はデータセットの平均 I/U スコアです。
また、Preview を通じて認識効果をより直感的に確認することもできます。以下のように、ファイルを追加してすべての鋼管の写真を選択します。
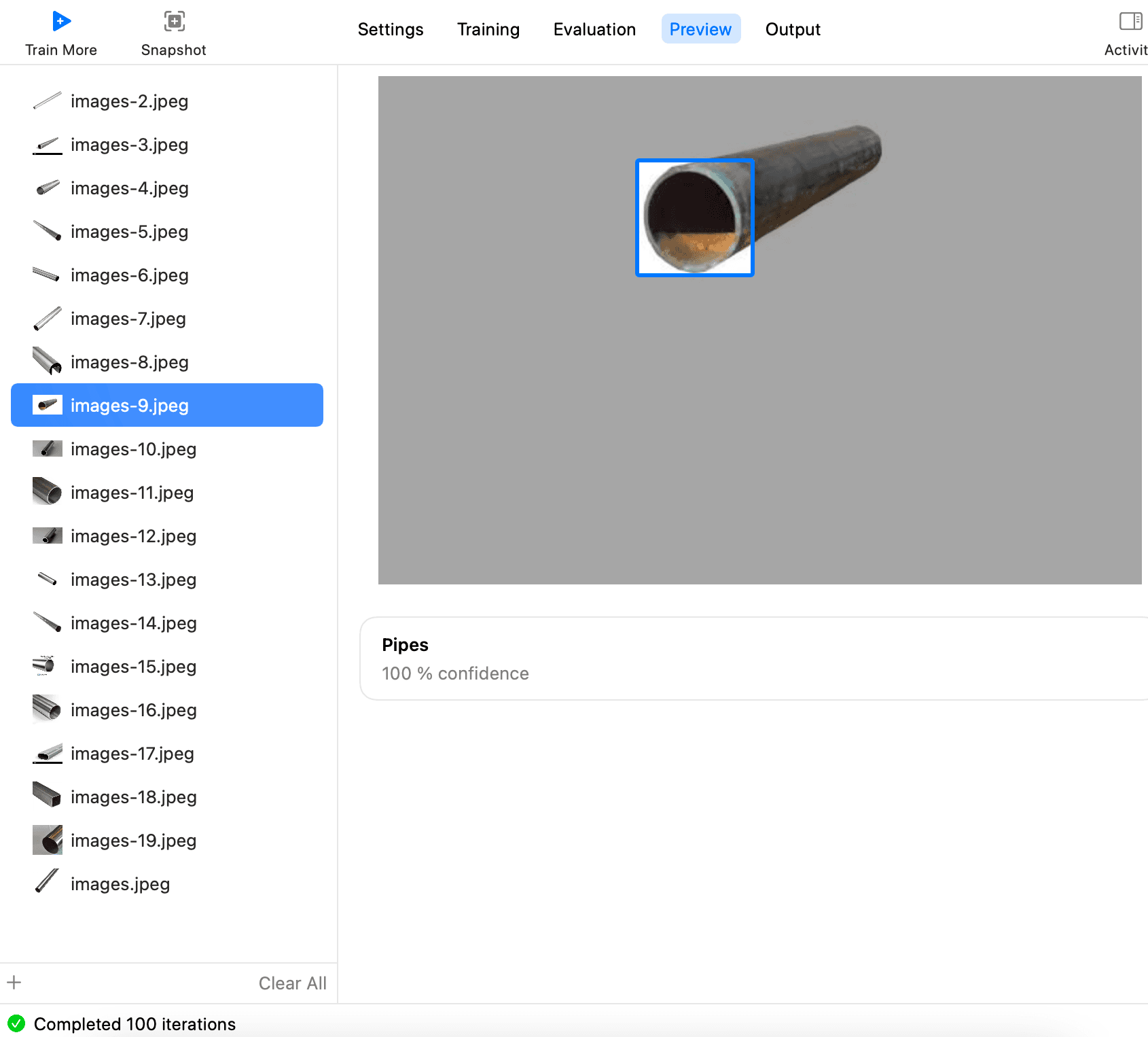
その後、一枚ずつ確認して、各写真が認識できるかどうかを確認します。
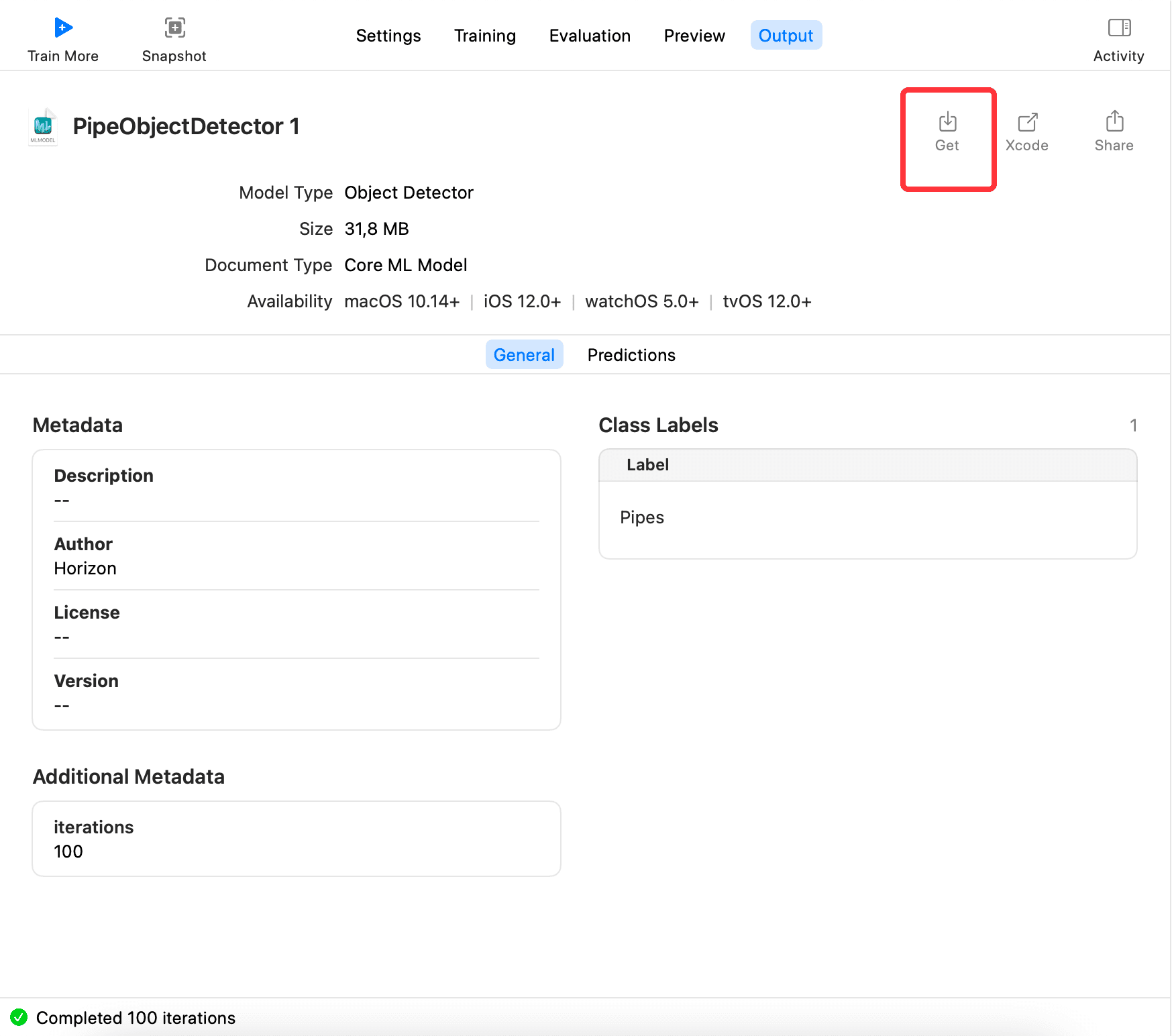
最後に、Output に切り替えてGetをクリックし、モデルxxx.mlmodelをエクスポートします。以下のようになります:
トレーニングされたモデル mlmodel の使用#
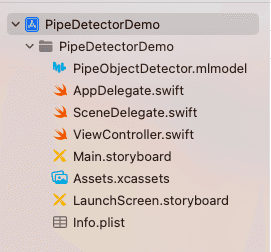
新しいプロジェクトを作成し、トレーニングされたモデルをプロジェクトにインポートします。以下のようになります:
次にVisionライブラリをインポートし、写真を 1 枚読み込み、VNImageRequestHandlerを生成し、生成されたハンドラーを使用して認識します。コードは以下の通りです:
class PipeImageDetectorVC: UIViewController {
// MARK: - properties
fileprivate var coreMLRequest: VNCoreMLRequest?
fileprivate var drawingBoxesView: DrawingBoxesView?
fileprivate var displayImageView: UIImageView = UIImageView()
fileprivate var randomLoadBtn: UIButton = UIButton(type: .custom)
// MARK: - view life cycle
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
setupDisplayImageView()
setupCoreMLRequest()
setupBoxesView()
setupRandomLoadBtn()
}
override func viewWillAppear(_ animated: Bool) {
super.viewWillAppear(animated)
}
// MARK: - init
fileprivate func setupDisplayImageView() {
view.addSubview(displayImageView)
displayImageView.contentMode = .scaleAspectFit
displayImageView.snp.makeConstraints { make in
make.center.equalTo(view.snp.center)
}
}
fileprivate func setupCoreMLRequest() {
guard let model = try? PipeObjectDetector(configuration: MLModelConfiguration()).model,
let visionModel = try? VNCoreMLModel(for: model) else {
return
}
coreMLRequest = VNCoreMLRequest(model: visionModel, completionHandler: { [weak self] (request, error) in
self?.handleVMRequestDidComplete(request, error: error)
})
coreMLRequest?.imageCropAndScaleOption = .centerCrop
}
fileprivate func setupBoxesView() {
let drawingBoxesView = DrawingBoxesView()
drawingBoxesView.frame = displayImageView.frame
displayImageView.addSubview(drawingBoxesView)
drawingBoxesView.snp.makeConstraints { make in
make.edges.equalToSuperview()
}
self.drawingBoxesView = drawingBoxesView
}
fileprivate func setupRandomLoadBtn() {
randomLoadBtn.setTitle("ランダムに画像を読み込む", for: .normal)
randomLoadBtn.setTitleColor(UIColor.blue, for: .normal)
view.addSubview(randomLoadBtn)
let screenW = UIScreen.main.bounds.width
let screeH = UIScreen.main.bounds.height
let btnH = 52.0
let btnW = 200.0
randomLoadBtn.frame = CGRect(x: (screenW - btnW) / 2.0, y: screeH - btnH - 10.0, width: btnW, height: btnH)
randomLoadBtn.addTarget(self, action: #selector(handleRandomLoad), for: .touchUpInside)
}
// MARK: - utils
// MARK: - action
fileprivate func handleVMRequestDidComplete(_ request: VNRequest, error: Error?) {
let results = request.results as? [VNRecognizedObjectObservation]
DispatchQueue.main.async {
if let prediction = results?.first {
self.drawingBoxesView?.drawBox(with: [prediction])
} else {
self.drawingBoxesView?.removeBox()
}
}
}
@objc fileprivate func handleRandomLoad() {
let imageName = randomImageName()
if let image = UIImage(named: imageName),
let cgImage = image.cgImage,
let request = coreMLRequest {
displayImageView.image = image
let handler = VNImageRequestHandler(cgImage: cgImage)
try? handler.perform([request])
}
}
// MARK: - other
fileprivate func randomImageName() -> String {
let maxNum: UInt32 = 18
let minNum: UInt32 = 1
let randomNum = arc4random_uniform(maxNum - minNum) + minNum
let imageName = "images-\(randomNum).jpeg"
return imageName
}
}
最終的な効果は以下の通りで、完全なコードは GitHub に掲載されています:CreateMLDemo

まとめ#
本記事ではCreateMLの全体的な流れを紹介しました。モデルのラベリングからモデルのトレーニング生成、モデルの使用まで、皆さんがCreateMLについて大まかな理解を得られることを願っています。今後、プロジェクトにインポートしたモデルが更新できるか、どのように更新するか、また自分の SMS フィルタリングアプリを作成することを試みたいと思います。
参考#
- Create ML
- Creating an Object Detection Machine Learning Model with Create ML
- Object Detection with Create ML: images and dataset
- Object Detection with Create ML: training and demo app
- On-device training with Core ML – part 1
- Core ML Explained: Apple's Machine Learning Framework
- A Gentle Introduction to Object Recognition With Deep Learning
- Turi Create